Patrones para migrar De Monolito a Microservicios

De Monolito a Microservicios
En este nuevo artículo vamos abordar el uso de algunos patrones para migrar de monolito a microservicios de diferentes maneras y siguiendo diferentes pautas o patrones. Cada vez esta más extendido el uso de microservicios en grandes arquitecturas, gracias en parte a su capacidad de aislamiento de responsabilidades, sus facilidades para ir a la nube, las responsabilidades únicas, tolerancia al fallo, facilidad de escalado etc…
Pero cuando tenemos una aplicación monolita y queremos abordar su posible migración nos encontramos con la típica pregunta de, ¿por dónde empezamos?, por funcionalidades, servicios, bases de datos, etc.
En este artículo pretendemos ver y explicar alguno de los patrones de microservicios más utilizados cuando queremos migrar nuestras arquitecturas a microservicios.
La típica arquitectura monolítica tiene todos los objetos y accesos a base de datos gestionados por un código muy acoplado. En la que toda la información se encuentra almacenada en una única base de datos. Y toda la lógica de negocio se encuentra en la aplicación cliente y servidor. Uno de los pasos a tener en cuenta cuando migramos nuestra arquictectura monolítica a microservicios será la migración de la Base de Datos. La cual habrá que migrar en diferentes schemas o bases de datos manteniendo las mismas funcionalidades.
Vamos a ver algunos de los patrones más comunes y utilizados en arquitecturas de migración de monolito a microservicios. Y también vamos a hablar de algunos patrones o formas de trabajar que nos puede ocasionar algún problema :(.
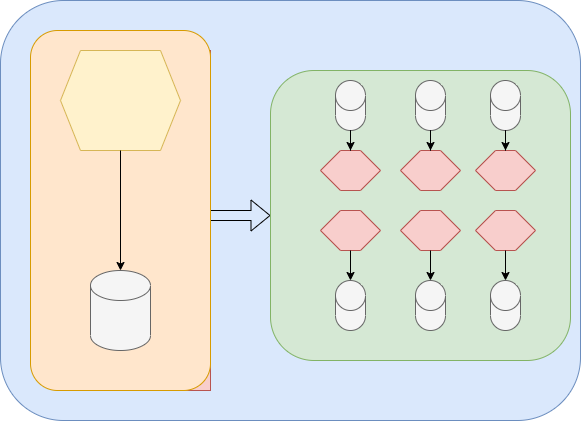
Reescritura Big Bang
Aunque suena muy atractivo poder hacer un Big Bang, como la palabra indica un Big Bang nos llevará a una gran explosión. Muchas veces cuando comenzamos a migrar a una arquitectura de microservicios pensamos en refactorizar y rehacer, pero esto nos va a complicar la migración al no reutilizar y aplicar patrones de migración. Reescribir supone invertir mucho tiempo en desarrollar el código que se encuentra en el monolito.
Si hacemos un Big Bang, todo el desarrollo, así como su lógica y funcionalidad se va a desarrollar de nuevo en nuestros microservicios. Este nuevo desarrollo va a ocasionar un mayor tiempo de desarrollo (que será más dinero), así como que cada nuevo cambio en el monolito se tiene que hacer en los microservicios o parar los desarrollos nuevos; a lo que en pocas ocasiones se estará de acuerdo.
Patrón Strangler Fig para migrar de Monolito a Microservicios
Cuando hablamos de patrones para migrar de monolito a Microservicios, Strangler Fig es uno de lo más conocidos y uno de los que más se suele aplicar. Desde mi experiencia, este es el más sencillo de utilizar y de aplicar en una migración de monolito a microservicios.
Este patrón (estrangulamiento de la higuera en español), se basa una comparación con una higuera real. Los higos comienzan en la rama y su raíz va bajando hasta el suelo, creciendo sin parar hasta «estrangular» al árbol padre. Si esta idea lo trasladamos a la migración de un monolito a una arquitectura de microservicios, la idea es ir creando microservicios hasta que eliminemos al software original.
Para lograr que este patrón funcione iremos creando nuevos servicios de manera perímetral a nuestro monolito. Es decir, los servicios más externos con funcionalidades unitarias los iremos migrando a microservicios. Vamos a ver un ejemplo mejor:
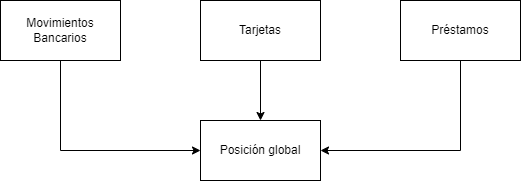
En el ejmplo anterior tenemos un monolito en el que tenemos las 4 funcionalidades que vemos en el dibujo. Para obtener la posición global es necesario llamar a Movimientos Bancarios, Tarjetas y Préstamos. Estas tres últimas funcionalidades podríamos considerarlas los bordes o el perímetro de nuestro monolito. Por lo que según el patrón Strangler Fig podríamos empezar la migración por los servicios más perímetrales como Movimientos Bancarios, tarjetas y préstamos y crear microservicios de esas funcionalidades.
Patrón de Ejecuciones paralelas o Parallel Run para migrar de monolito a Microservicios
Obviamente cuando creamos software este puede fallar, y lo que tenemos que lograr es detectar y minimizar esos errores y fallos. Y en el caso en el que migremos un software que ya se encuentra en producción habrá que tener más cuidado todavía. Para evitar problemas e ir testeando nuestro software a medida que desarrollamos podemos utilizar Parallel Run como uno de los patrones para migrar de monolito a Microservicios
Para minimizar riesgos en nuestra migración vamos a ejecutar de manera paralela nuestro nuevo microservicio y la funcionalidad del monolito. La fuente de verdad será el monolito y el que se encargará de resolver las peticiones pero también le llegará la información al microservicio y la respuesta será contrastada con el monolito. Una posible acción para verificar que todo es correcto puede ser almacenar ambas respuestas y contrastarlas con un proceso batch, de esta manera podremos resolver errores en nuestro microservicio.
Patrón Branch By Abstraction
El patrón Branch By Abstraction nos permite ir sacando funcionalidades cuando el sistema esta en uso. Este patrón es perfecto para aquellos casos en los que esa funcionalidad depende de otras funcionalidades o módulos.
La idea de este patrón es permitir que la funcionalidad que ya existe, como la nueva implementación de esa funcionalidad coexistan dentro del mismo proceso en ejecución al mismo tiempo. Para lograr este patrón creamos una capa de abstracción sobre la funcionalidad que queremos implementar.
Este proceso lo podríamos dividir en varias etapas:
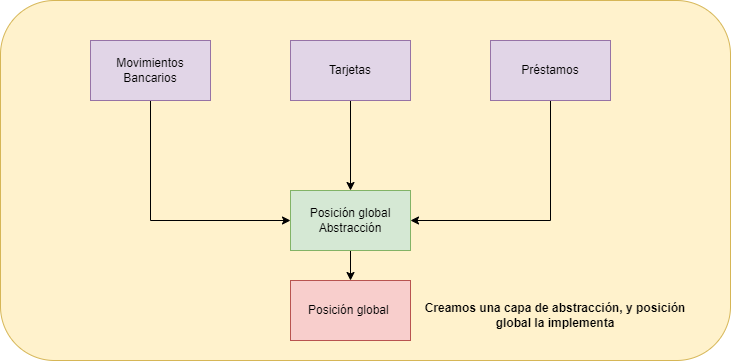
- Crear la capa de abstracción: Creamos una capa de abstracción sobre el módulo al que vamos a llamar.
- Refactorización: Se ha de modificar el código para que se llame a esta nueva capa en lugar de directamente a la funcionalidad antigua.
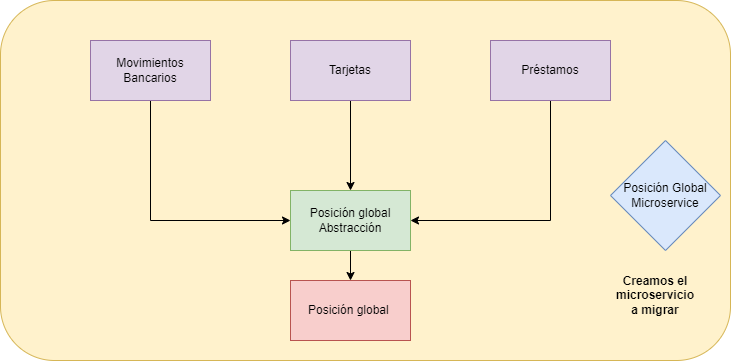
- Creación del microservicio: Una vez conocemos la funcionalidad a reemplazar y tenemos creada la capa de abstracción es momento de crear un microservicio con esa funcionalidad.
- Migración: Una vez hemos creado el nuevo microservicio, y ha sido testeado podremos ir poco a poco conectando el nuevo microservicio para que resuelva todas las peticiones.
Vamos a ver estos pasos partiendo del dibujo anterior en el que vamos a migrar Movimientos Bancarios:
Creamos la capa de abstracción y conectamos la funcionalidad que queremos migrar:
Creamos el microservicio:
Conectamos el Microservicio:
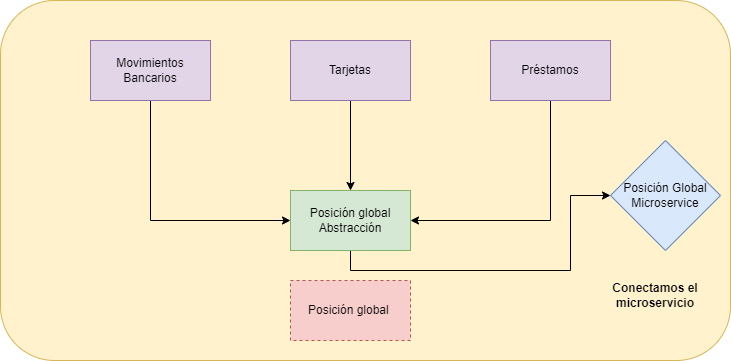
Eliminamos la antigua funcionalidad:
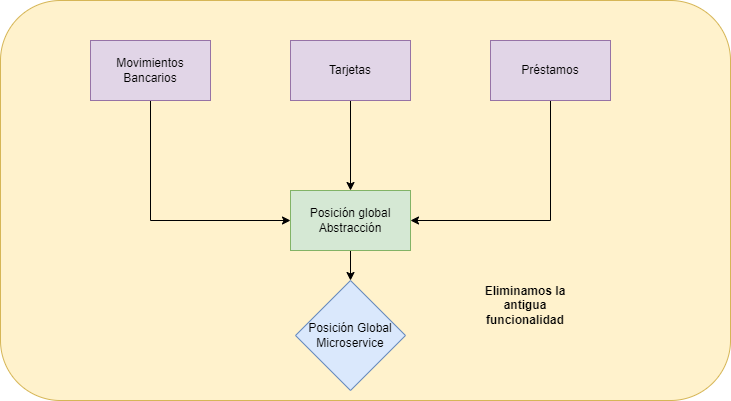
Un monolito suele tener una única base de datos en la que se guardan todas las funcionalidades, pero cuando pasamos a una arquitectura de microservicios lo normal es tener un schema o base de datos por microservicio. Por lo que vamos a ver algunos patrones de migración de bases de datos cuando pasamos de un monolito a microservicios.
Patrones para Bases de Datos compartidas
Patrón Vista de Base de Datos o Database View
Cuando venimos de una arquitectura en la que compartimos nuestra base de datos con todos los servicios y queremos que se siga manteniendo una Base de Datos compartida en nuestra arquitectura de microservicios, la aproximación de generar vistas es la más correcta. Con una vista, un servicio puede acceder a la Base de Datos como si fuera un schema, permitiendo visualizar únicamente la información que pertenece a ese servicio. Está puede ser una buena aproximación para emplear como patrones para migrar de monolito a Microservicios ya que nos va a permitir aislar nuestra base de datos y poco a poco ir desacoplando nuestro monolito.
Haciendo uso de vistas vamos a poder controlar el acceso a datos a los datos para nuestro microservicio, de manera que vamos a poder ocultar el resto de datos o la información que no requiera.
Aunque esta pueda ser una medida a tomar y considerar cuando realizamos nuestra migración a microservicios tenemos que tener en cuenta que tiene limitaciones:
- Una vista es solo de lectura, lo que ya limita su utilidad.
- La gran mayoría de Bases de Datos NoSQL no permiten vistas.
- Acoplamiento debido a que se usa una misma Base de Datos.
- El escalado se tiene que realizar a toda la Base de Datos.
- Único punto de fallo.
Patrón Envoltura de Base de Datos o Database Wrapping Service
Cuando en alguna de nuestras migraciones veamos que se nos complica mucho crear vistas o tratar con la información específica de la Base de Datos o que el DBA o el equipo responsable de los Datos no permitan realizar migraciones o modificaciones sobre la Base de Datos podemos hacer uso de DataBase Wrapping Service como uno de los patrones de migración de monolito a Microservicios. Este patrón nos permite la creación de un servicio que envuelva nuestra Base de Datos y nos devuelva lo que necesite.
El patrón Database Wrapping Service, nos ofrece algunas ventajas como:
- Una única vista de Base de Datos, lo que nos permitirá escirturas y lecturas.
- Uso de un servicio intermedio que nos permitirá devolver los datos que deseemos.
- Permite la creación de un API de consumo de la Base de Datos.
- Proporciona tiempo para reajustar o dividir la Base de Datos en Schemas o en más Bases de Datos.
Patrón Database as a Service Interface
Pueden existir ocasiones en las que en nuestra arquitectura únicamente tengamos una Base de Datos sobre la que realicemos consultas. Por los que para estas ocasiones, tiene sentido permitir que se puedan ver los datos que el servicio administra. Lo único que en estos casos habrá que tener en cuenta tener separadas las Bases de Datos que exponemos y la que se encuentra en los límites de nuestro servicio.
Para llevar a cabo el patrón Database as a Service Interface, podemos utilizar la aproximación de crear una Base de Datos dedicada como solo lectura que pueda ser accedida fuera de los límites de nuestro servicio a través de un API expuesta hacia afuera y actualizarla cuando la Base de Datos interna cambie; y una Base de Datos dentro de nuesto servicio. Para el proceso de actualización de nuestra Base de Datos de solo lectura tendremos un motor que se encargará de popular la Base de Datos.
Vamos a verlo con un dibujo:
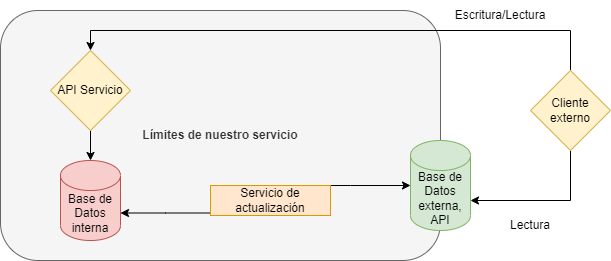
En el dibujo anterior vemos como tendremos dos Bases de Datos la de interna de nuestro servicio que permitirá lecturas y escrituras y la que permite el acceso externo de únicamente lectura. Además vemos una pieza clave en este patrón el servicio de actualización o mapping engine que funciona como una capa de abstracción. Esta permitirá la actualización de nuestra base de datos cuando existan cambios para mantener la consistencia de datos de nuestro sistema.
Ventajas e inconvenientes de Database-as-a-Service Interface:
- Presenta mayor complejidad que otros patrones de Bases de Datos compartida.
- Ofrece una mayor flexibilidad que el uso de vistas.
- Aislamos las lecturas de las escrituras.
- Es perfecto para aquellos clientes que únicamente necesitan lecturas.
- Requiere un mayor esfuerzo y por tanto inversión de tiempo mayor a otros patrones.
Hasta este punto hemos visto como mitigar o disminuir el esfuerzo a través de pautas o patrones para migrar de monolito a Microservicios cuando compartimos Bases de Datos. Vamos a ver como podemos dividir nuestra Base de Datos en función de nuestros microservicios.
Sincronización de Datos con múltiples Bases de Datos para migrar De Monolito a Microservicios
Cuando estamos migrando nuestra arquitectura a microservicios, y hacemos uso por ejemplo de Strangler Fig, vamos a tener conviviendo tanto microservicios como nuestro monolito. En este caso van, también, a vivir conjuntamente la Base de Datos compartida y las Bases de Datos de nuestros microservicios.
Durante el tiempo que ambas arquitecturas tengan que convivir, todas las Bases de Datos van a tener que estar sincronizadas.
Para enfrentarnos a este problema y encontra la mejor solución posible, habrá que analizar que necesitamos, si una Base de Datos compartida, por lo que podríamos crear vistas; si nos encontramos ante un Big Ban por lo que podríamos usar un Batch o un Stream de Datos por ejemplo con Kafka y KSQL para la migración etc…
Patrón Trace Writer
Este patrón nos va a permitir ir migrando la Base de Datos del monolito que es nuestra fuente de verdad, a la nueva Base de Datos de nuestro microservicio de una manera incremental. En este momento estarán conviviendo dos bases de datos, por lo que habrá que tener en cuenta la sincronización para evitar inconsistencias de Datos. Y de esta manera el nuevo código usará la nueva Base de Datos como fuente de verdad, este nuevo código será el desarrollado en el nuevo microservicio.
La idea del patrón trace writer es hacer releases incrementales de manera que no hagamos un switch abarcando todas las funcionalidades, ya que esto, nos podría llevar a generar muchos problemas e inconsistencias. Con cada release tendremos nuevas funcionalidades con lo que podremos ir desconectando los clientes de la antigua fuente de verdad y conectarlos a la nueva fuente de verdad.
Una vez hemos finalizado con tadas las funcionalidades, ya no será necesario tener los dos orígenes de datos y la antigua fuente de verdad podrá ser desconectada una vez todos los consumidores se conectan a la nueva Base de Datos.
Hay que tener en cuenta que vamos a tener dos fuentes de verdad, por lo que, por un lado habrá que evitar inconsistencias, y por otro hay que mantener los datos sincronizados aunque eso haga que tengamos duplicados.
Otro de los factores que vamos a tener que preveer con este patrón es la consistencia eventual de los datos. Cuando realizamos sincronizaciones, por ejemplo con un CDC (Change Data Capture System), podemos tener fragmentos de tiempo en los que nuestros datos estén inconsistentes, por lo que esos tiempos habrá que evaluarlos y tenerlos en cuenta.
Dividir la Base de Datos en nuestra migración de Monolito a Microservicios
Cuando nos enfrentamos a la migración de una arquitectura monolítcia a Microservicios puede ser que queramos abordar la división y ruptura de nuestra Base de Datos del monolito, y dividirla para que cada microservicio tenga su propia Base de Datos. Para estos casos, en los que adentrarse en esa ruptura puede ser complicada, existen algunos patrones, pasos y sugerencia que podemos seguir para intentar simplificar el trabajo, aunque dividir una Base de Datos siempre será bastante complicado.
Para dividir la Base de Datos, lo primero que deberemos tener en cuenta es si queremos comenzar primero por la división del código y crear nuestros microservicios o comenzar primero por la división de la Base de Datos para luego ir hacia la división del código.
Comenzar con la divisón del código primero
La ventaja de comenzar primero por el código primero es que vamos a tener más claro cuales son los datos que vamos a necesitar en nuestro microservicio. De esta manera luego podremos abordar esa separación con las ideas más claras. Para poder abordar esta tarea podemos usar el patrón Monolith as data access layer el cual se basa en crear un API delante del monolito para la obtención de datos. De esta manera podremos seguir desarrollando nuestro microservicio y a continuación «romper» nuestra Base de Datos. O tambíen podemos utilizar la aproximación Multischema Storage, en la que nuevas tablas o funcionalidades podemos añadirlas a nuevos schemas.
Dividir la Base de Datos primero
Cuando mantenemos nuestro código, es decir, nuestro monolito y decidimos dividir la Base de Datos primero, vamos a tener que realizar modificaciones sobre nuestro código ya que ahora habrá que hacer queries contra varias Bases de Datos o Schemas. De manera que lo que previamente conseguíamos con una única query, ahora realizaremos varias y tendremos que hacer sus respectivas Joins en memoria. A pesar de este inconveniente, vamos a poder verificar los cambios que vamos haciendo sin afectar a los clientes conectados, de modo, que ante cualquier error podremos volver hacia atrás más fácilmente.
Por otro lado, nos encontraremos problemas como la transaccionalidad que tendrán que ser tratados con múltiples transacciones. Para poder abordar esta aproximación podemos hacer uso del Patrón Repository per bounded context, que sugiere la idea de añadir una capa repository con algún framework como Hibernate para poder mapear objetos de Base de Datos de una manera más fácil.
Dividir Base de Datos y Código a la vez
Obviamente podemos dividir tanto código como Base de Datos de manera simúltanea, ¿por qué no?, pero esta aproximación nos llevará muchos más esfuerzos y tiempo, y además volver atrás ante problemas o errores también será mucho más costoso.
Conclusión
Estos han sido algunas sugerencias y Patrones para migrar De Monolito a Microservicios, aunque sin duda hay muchos más o incluso puedes hacer híbridos entre diferentes patrones.
Obviamente algunos temas o problemas irán surgiendo durante la migración, por ejemplo, el tratamiento de la transaccionalidad en Base de Datos, a lo que habrá que ir a patrones de microservicios como Sagas, o dividir una tabla a través de varios servicios, etc. Sea como sea, una migración a una arquitectura de microservicios puede ser larga y compleja, por lo que antes de comenzar habrá que analizar bien como la vamos abordar.
Si necesitas más información puedes escribirnos un comentario o un correo electrónico a refactorizando.web@gmail.com o también nos puedes contactar por nuestras redes sociales Facebook o twitter y te ayudaremos encantados!
Un buen artículo de introducción para presentar todas estas ideas de transformación hacia una arquitectura de microservicios. Enhorabuena
Muchas gracias, me alegra que te haya gustado.