Streaming de datos con KSQL en Kafka

Streaming de datos con KSQL
En esta entrada sobre streaming de datos con KSQL en Kafka, vamos a probar KSQL a través de su instalación mediante docker. Además veremos las características principales de este motor SQL para los stream en kafka.
La rápida expansión y crecimiento de la explotación de datos así como su consumo en tiempo real, conlleva la creación de herramientas que puedan realizar ese trabajo. Para cubrir esas necesidades surgen diferentes herramientas como KSQL.
KSQL permite desarrollar aplicaciones de streaming sobre un sistema escalable, elástico y tolerante a fallos. Proporciona una interfaz SQL para procesamiento de flujos de datos con operaciones de filtrado, transformación, agregación y con posibilidad de usar ventanas de procesamiento. Está desarrollado por Confluent y distribuido con licencia open source.
¿Qué es KSQL?
Podríamos definir KSQL como un envoltorio en la capa superior del API de Kafka Streams que nos va a facilitar el trabajo con Streams de Kafka haciendo consultas SQL. Todo esto sin la necesidad de escribir código complejo o en algún lenguaje de programación. Además su flexibilidad nos permite un amplio rango de operaciones de streaming, como transformaciones, agregaciones, joins, windowing…, etc.
KSQL nos va a permitir desarrollar aplicaciones de streaming sobre un sistema escalable, elástico y tolerante a fallos. Proporciona una interfaz SQL para procesamiento de flujos de datos con operaciones de filtrado, transformación, agregación y con posibilidad de usar ventanas de procesamiento. Está desarrollado por Confluent y distribuido con licencia open source.
Recomiendo echar un vistazo a la documentación de confluent para conocer más sobre los tipos de datos y las queries que se pueden aplicar.
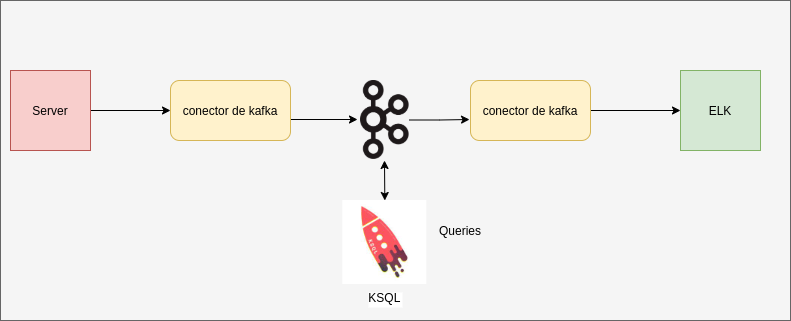
Configuración de KSQL
Para realizar nuestra instalación y configuración vamos a hacer uso de docker a través de un docker-compose. Los servidores de KSQL se pueden separar en diferentes máquinas de donde se encuentra el clúster de kafka broker. Para conectarnos al servidor de KSQL lo haremos con el cliente de KSQL a través de HTTP.
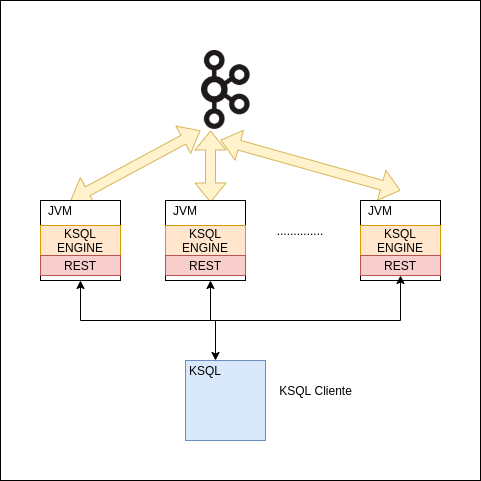
A continuación vamos a ejecutar el siguiente docker-compose en nuestro local:
version: '3.5'
services:
zookeeper:
image: "confluentinc/cp-zookeeper:5.3.0"
hostname: zookeeper
networks:
- ksql-net
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka:
image: "confluentinc/cp-enterprise-kafka:5.3.0"
hostname: kafka
networks:
- ksql-net
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"
KAFKA_DELETE_TOPIC_ENABLE: "true"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_METRIC_REPORTERS: "io.confluent.metrics.reporter.ConfluentMetricsReporter"
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: "kafka:9092"
schema-registry:
image: "confluentinc/cp-schema-registry:5.3.0"
hostname: schema-registry
networks:
- ksql-net
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: zookeeper:2181
SCHEMA_REGISTRY_LISTENERS: http://schema-registry:8081
# Runs the Kafka KSQL data generator for topic called "pageviews"
ksql-datagen-pageviews:
image: "confluentinc/ksql-examples:5.3.0"
networks:
- ksql-net
restart: always
command: "bash -c 'echo Waiting for Kafka to be ready... && \
cub kafka-ready -b kafka:9092 1 20 && \
echo Waiting for Confluent Schema Registry to be ready... && \
cub sr-ready schema-registry 8081 20 && \
echo Waiting a few seconds for topic creation to finish... && \
sleep 2 && \
/usr/bin/ksql-datagen
quickstart=pageviews format=delimited topic=pageviews bootstrap-server=kafka:9092 maxInterval=100 iterations=1000 && \
/usr/bin/ksql-datagen
quickstart=pageviews format=delimited topic=pageviews bootstrap-server=kafka:9092 maxInterval=1000'"
environment:
KSQL_CONFIG_DIR: "/etc/ksql"
KSQL_LOG4J_OPTS: "-Dlog4j.configuration=file:/etc/ksql/log4j-rolling.properties"
STREAMS_BOOTSTRAP_SERVERS: kafka:9092
STREAMS_SCHEMA_REGISTRY_HOST: schema-registry
STREAMS_SCHEMA_REGISTRY_PORT: 8081
# Runs the Kafka KSQL data generator for topic called "users"
ksql-datagen-users:
image: "confluentinc/ksql-examples:5.3.0"
networks:
- ksql-net
restart: always
command: "bash -c 'echo Waiting for Kafka to be ready... && \
cub kafka-ready -b kafka:9092 1 20 && \
echo Waiting for Confluent Schema Registry to be ready... && \
cub sr-ready schema-registry 8081 20 && \
echo Waiting a few seconds for topic creation to finish... && \
sleep 2 && \
/usr/bin/ksql-datagen
quickstart=users format=json topic=users bootstrap-server=kafka:9092 maxInterval=100 iterations=1000 && \
/usr/bin/ksql-datagen
quickstart=users format=json topic=users bootstrap-server=kafka:9092 maxInterval=1000'"
environment:
KSQL_CONFIG_DIR: "/etc/ksql"
KSQL_LOG4J_OPTS: "-Dlog4j.configuration=file:/etc/ksql/log4j-rolling.properties"
STREAMS_BOOTSTRAP_SERVERS: kafka:9092
STREAMS_SCHEMA_REGISTRY_HOST: schema-registry
STREAMS_SCHEMA_REGISTRY_PORT: 8081
ksql-server:
image: "confluentinc/cp-ksql-server:5.3.0"
ports:
- "8088:8088"
networks:
- ksql-net
environment:
KSQL_CONFIG_DIR: "/etc/ksql"
KSQL_LOG4J_OPTS: "-Dlog4j.configuration=file:/etc/ksql/log4j-rolling.properties"
KSQL_BOOTSTRAP_SERVERS: "kafka:9092"
KSQL_HOST_NAME: ksql-server
KSQL_APPLICATION_ID: "etl-demo"
KSQL_LISTENERS: "http://0.0.0.0:8088"
KSQL_CACHE_MAX_BYTES_BUFFERING: 0
KSQL_KSQL_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
KSQL_PRODUCER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor"
KSQL_CONSUMER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor"
ksql-cli:
image: confluentinc/cp-ksql-cli:5.3.0
networks:
- ksql-net
entrypoint: /bin/sh
tty: true
networks:
ksql-net:
El fichero anterior lo guardamos en nuestro local y lo llamamos por ejemplo, docker-compose-ksql.yaml. Una vez guardado lo ejecutamos con el siguiente comando:
docker-compose -f docker-compose-ksql.yaml up
y ejecutamos el cliente ksql con el comando:
docker-compose -f docker-compose-ksql.yaml exec ksql-cli ksql http://ksql-server:8088
Al ejecutar el comando anterior veremos algo así:
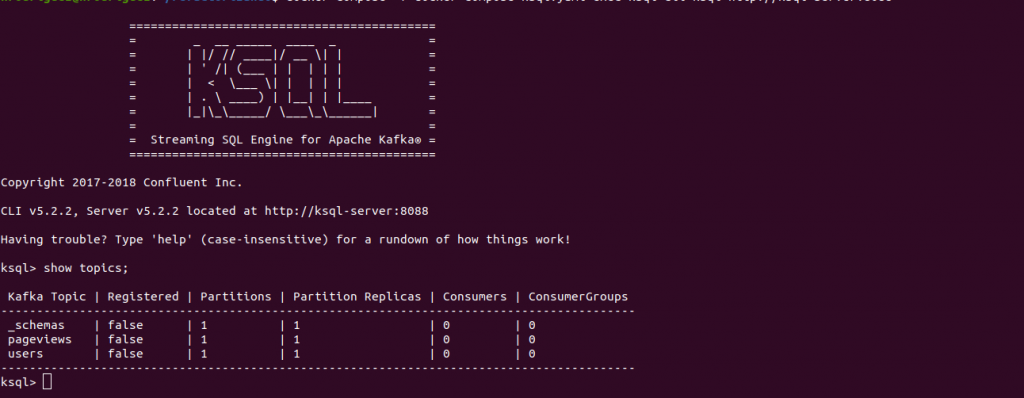
En la foto anterior podemos ver los topics que tenemos como las réplicas y particiones. Si hemos analizado el docker-compose anterior hemos podido ver como hay una aplicación que se llama ksql-datagen-users, esta aplicación hace uso del topic users, por lo que vamos a ver los datos producidos desde el principio, para eso ejecutamos el siguiente comando.
docker-compose -f docker-compose-ksql.yaml exec kafka kafka-console-consumer --bootstrap-server kafka:9092 --topic users —from-beginning
Al igual que con el topic users vamos a hacer lo mismo con el pageviews. En el docker-compose también podemos ver esta aplicación, que es un generador de datos para el topic pageviews, y ejecutando el siguiente comando podemos ver su funcionamiento:
docker-compose -f docker-compose-ksql.yaml exec kafka kafka-console-consumer --bootstrap-server kafka:9092 --topic pageviews —from-beginning
Ejemplos y usos en KSQL
Vamos a ver algún ejemplo básico como sus comandos en KSQL, para ello vamos a partir de la configuración que hemos realizado anteriormente en nuestro docker-compose. Entre los ejemplos vamos a ver como crear y definir un stream con KSQL, como crear una tabla y qué es una tabla en KSQL, así como crear queries, y finalizar y borrar todo lo creado.
Creación de Streams con KSQL
A continuación vamos a comenzar a jugar con los streams de kafka, para ello vamos a comenzar creando uno para el topic pageviews de la siguiente manera:
CREATE STREAM pageviews (viewtime BIGINT,userid VARCHAR,pageid VARCHAR) WITH (KAFKA_TOPIC='pageviews',VALUE_FORMAT='DELIMITED');
El formato DELIMITED soporta valores separados por coma, se pueden usar otros formatos.
En el stream hemos definido los tipos de los datos y el topic del stream. Al igual que definimos una key cuando envíamos un mensaje a un topic de kafka, podemos crear también un key al crear el Stream, el mecanismo es parecido que cuando se crea una tabla de sql.
CREATE STREAM pageviews_withkey
(viewtime BIGINT,
userid VARCHAR,
pageid VARCHAR)
WITH (KAFKA_TOPIC='pageviews',
VALUE_FORMAT='DELIMITED',
KEY='pageid
Una vez que hemos creado nuestros streams podemos ver los streams a través de la consola con el comando:
show streams
Streams con condiciones
Como hemos comentado anteriormente, KSQL nos va a permitir hacer consultas SQL sobre streams. Por lo que al igual que hacemos con la cláusula where en nuestras consultas de sql lo podemos hacer en KSQL. En el stream que hemos creado antes vamos a añadir una cláusula where en el que vamos a filtrar por pageid.
CREATE STREAM pageviews_where AS
SELECT * FROM pageviews
WHERE pageid < 'Page_20';
Al igual que hemos hecho para visualizar los streams creados, podemos hacer para ver las queries que vamos creando:
show queries;
Creación de Tablas en KSQL
Una tabla en KSQL podríamos definirlo como el estado de hoy. Una tabla representa el estado en un momento actual. A diferencia de un stream que representa una secuencia de eventos desde el principio a hoy.
Usaremos Streams cuando tengamos una serie de eventos que analizar o monitorizar, y en cambio cuando tengamos alguna agregación, como máximos, mínimos, medias etc, trabajaremos con tablas.
Para crear tablas en KSQL vamos a hacer uso del comando CREATE TABLE. Al crear una tabla con KSQL, a diferencia que con los Streams, vamos a necesitar específicar una key.
CREATE TABLE users
(registertime BIGINT,
gender VARCHAR,
regionid VARCHAR,
userid VARCHAR,
interests array<VARCHAR>,
contactinfo map<VARCHAR, VARCHAR>)
WITH (KAFKA_TOPIC='users',
VALUE_FORMAT='JSON',
KEY = 'userid');
También vamos a poder usar el comando CREATE TABLE como una select, es decir, vamos a crear una tabla que nos devuelva el resultado de una query.
Por ejemplo vamos crear una tabla para obtener un contador de la regionid y lo agrupamos por regionId;
CREATE TABLE users_by_region AS SELECT regionid, count(*) FROM users GROUP BY regionid;
Recuerda añadir el GROUP BY si haces una agregación.
En el caso anterior se creará una query aparte de la tabla para mostrar los resultados, si quieres ver la nueva query puedes hacer show queries;

Una vez creada la tabla podemos hacer uso del comando, SHOW TABLES, para ver las tablas que tenemos creadas:

Uso Joins en KSQL
Al igual que ocurre con una base de datos relacional, a veces queremos cruzar datos entre tablas para obtener una query, esto lo hacemos a través de Joins, tanto en SQL como en KSQL.
Con el uso de joins en KSQL podremos hacer:
- Crear un nuevo stream haciendo Join sobre dos streams.
- Crear una nueva tabla haciendo Join sobre dos tablas.
- Hacer un Join sobre una tabla y un stream para generar un nuevo stream.
Vamos a ver un ejemplo de Join partiendo del stream que creamos anteriormente llamado pageviews:
CREATE STREAM pageviews_join AS SELECT users.userid AS userId, pageid, regionid, gender FROM pageviews LEFT JOIN users ON pageviews.userid = users.userid;
Ahora si hacemos un select * from pageviews_join podremos ver la join creada con pageviews y users.
Borrar Tablas y Streams en KSQL
Para borrar cualquier tabla o stream en KSQL es suficiente con utilizar el comando DROP indicando el tipo que es por ejemplo:
DROP TABLE/STREAM name;
Pero antes de borrar cualquier stream o tabla hay que asegurarse que ha finalizado la query asociada, utilizando el comando TERMINATE.
TERMINATE nombre_query;
Conclusión
En esta entrada sobre Streaming de datos con KSQL en Kafka hemos visto lo que KSQL nos puede ofrecer para hacer explotación de nuestros eventos en kafka y poder trabajar con ellos en tiempo real como herramienta de análisis de datos.
Su fácil instalación ya sea a través de docker o haciendo uso de los paquetes de instalación proporcionados, nos va a permitir comenzar a explotar la información de manera rápida y eficaz en muy poco tiempo.
Si necesitas más información puedes escribirnos un comentario o un correo electrónico a refactorizando.web@gmail.com y te ayudaremos encantados!
No te olvides de seguirnos en nuestras redes sociales Facebook o Twitter para estar actualizado.