Schema Registry con Kafka Stream y Avro en Spring Boot

Kafka-Stream-Schema-Registry
En un artículo anterior vimos qué es y por qué habría que hacer uso de Schema Registry con Kafka, en esta entrada vamos a ver mediante un ejemplo de Schema Registry con Kafka Stream y Avro en Spring Boot su uso en una aplicación.
El uso de eventos en nuestras arquitecturas de microservicios, es cada vez más habitual por lo que herramientas como Schema Registry haciendo uso de kafka será una útil herramienta dentro de nuestro sistema.
Schema Registry nos va a facilitar guardar los schemas de nuestros eventos que envíamos a Kafka. De esta manera, se encargará de la gestión y distribución de los esquemas entre productor y consumidor.
Existen diferentes tipos de serializador y deserializador y en nuestro ejemplo vamos a hacer uso de Avro que es uno de lo más usados con Schema Registry.
¿Qué es Schema Registry?
Schema Registry es una capa que nos ofrece almacenamiento de nuestros esquemas de eventos. De manera que el formato de nuestros eventos van a quedar almacenado en un servidor que se encuentra fuera de nuestro clúster de Kafka. Y a donde nuestro consumidor y productor tendrán que ir para consultar el schema del evento a enviar y recibir.
¿Qué es Kafka Streams?
Kafka Streams es una librería para la creación de aplicaciones streaming, transforman un topic de entrada en uno de salida.
A diferencia de la API de consumidor de Kafka, el API de Kafka Stream nos va a permitir realizar el consumo de datos en stream desde un topic. Permitiendo paralelismo, coordinación distribuida, escalabilidad y una gran tolerancia al fallo. Va a permitir tratar con procesos real time y procesamiento continuo de información. Entre las principales características de Kafka Stream podemos encontrar:
- Un simple Stream de Kafka para envíar y producir.
- No aguanta procesamiento en Batch.
- Soporta operaciones con y sin estado.
- Pocas líneas de código para implementarlo.
- MultiThread y paralelismo.
- Interactúa con un solo clúster de Kafka.
Abstracciones en Kafka Stream: KStream, KTable y GloablKTable
La principal característica de Kafka Stream es el poder hacer uso de tablas. Es decir, Kafka Streams, admite streams de datos, pero también tablas que nos va a permitir la transformación de manera bidireccional. Es lo que se conoce como stream-table-duality
Las tablas van a ser una serie de acciones o hechos que se encuentran en continua evolución, cada nuevo evento que se procesa sobreescribe el anterior, por otro lado, los streams de datos son hechos pero en este caso inmutables.
Para poder hacer uso de Tablas dentro de Kafka Streams, tenemos dos abstracciones, por un lado KStream y por otro lado KTable. Con KStream manejamos el registro de los streams que nos llegan y con KTable vamos a gestionar el changelog stream con la última versión de una clave dada. Cada registro de información va a representar un estado.
Y por otro lado tenemos GlobalKTable, que es una abstracción para tablas no particionadas. Podemos hacer uso de GlobalKTable para enviar información a todas las tareas o hacer uniones entre tablas sin necesidad de particionar los datos de entrada.
Cada Kafka Stream proporciona para la serialización y deserialización una librería llamada SerDes. Vamos ver como podemos hacer uso de estas tres abstracciones que acabamos de ver:
StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> data = builder.stream(topic, Consumed.with(Serdes.String(), Serdes.String()));
StreamsBuilder builder = new StreamsBuilder(); KTable<String, String> data = builder.table(topic, Consumed.with(Serdes.String(), Serdes.String()));
StreamsBuilder builder = new StreamsBuilder(); GlobalKTable<String, String> data = builder.globalTable(topic, Consumed.with(Serdes.String(), Serdes.String()));
Ejemplo de Kafka Streams
El siguiente ejemplo se encuentra en Github si quieres puedes descargarlo aquí.
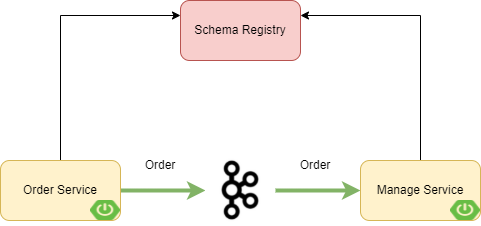
Arquitectura del Ejemplo
Nuestro ejemplo va a consistir en un concesionario de coches en el que se realizan compras. Desde nuestro Order Service se enviará un mensaje haciendo uso de Kafka Stream.
Para realizar el ejemplo vamos a tener dos diferentes servicios, por un lado Order Service y por otro lado Manage Service, en el que en el primero realizará haciendo uso de Avro para la serialización un evento cuando se realize una compra de un coche. Y el servicio Manage Service se encargará de actualizar el stock de coches. Para ello se hará uso del topic order.
Además contaremos con un Schema Registry al que tanto nuestro consumidor como productor se encontraran unidos para realizar la verificación de los schemas de los mensajes que le llegan, a través de una serialización y deserialización con Avro.
Configuración de Kafka y Schema Registry
Vamos a comenzar la configuración de nuestro ejemplo ejecutando una instancia de Kafka y de Schema registry para la comunicación entre nuestros servicios,para ello vamos a hacer uso del siguiente Docker-Compose que ya vimos en nuestro ejemplo de Schema Registry.
version: '3'
services:
# kafka cluster.
kafka-cluster:
image: landoop/fast-data-dev:latest
environment:
ADV_HOST: 127.0.0.1
RUNTESTS: 0
FORWARDLOGS: 0
SAMPLEDATA: 0
ports:
- 2181:2181 # Zookeeper port
- 3030:3030 # Landoop UI port
- 8081-8083:8081-8083 # REST Proxy, Schema Registry, Kafka Connect ports
- 9581-9585:9581-9585 # JMX Ports
- 9092:9092 # Kafka Broker port
Ejecutamos:
docker-compose up #-d para ejecutar en background
Y tendremos una instancia de Kafka levantada y un Schame Registry en http://localhost:3030.
Dependencias Maven
Una vez tenemos nuestro Kafka y Schema Registry levantado y funcionando vamos a configurar las dependencias maven necesarias para nuestro consumidor y productor
Dependencias Maven Productor
Para comenzar vamos a hacer uso de la librería de spring boot de kafka streams
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-kafka</artifactId> </dependency>
Además como vamos a hacer uso de Avro y de Schema Registry vamos a necesitar las dependencias de Avro y de Schema Registry de confluent por lo que vamos a añadir el repositorio de confluent y a continuación las dependencias de Avro y Schema Registry:
<repositories>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>${kafka-avro-serializer.version}</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-compiler</artifactId>
<version>${avro.version}</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>${avro.version}</version>
</dependency>
Además vamos a hacer uso del plugin de maven de Avro para generar a partir del Schema las clases Java:
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>${avro-plugin.version}</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>src/main/avro</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
Dependencias Maven Consumidor
Añadiremos la dependencia de binder de kafka Streams. El resto de dependencias y plugin serán igual que en el productor para poder hacer uso de Avro y Schema Registry.
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-stream-binder-kafka-streams</artifactId> </dependency>
Configuración de los propiedades de para Kafka Stream con Schema Registry y Avro
Vamos a hacer uso de la autoconfiguración de Spring para configurar nuestros servicios a través de los ficheros de propiedades.
Productor
spring:
application:
name: order-car
cloud:
schema:
avro:
dynamicSchemaGenerationEnabled: true
stream:
default:
contentType: application/*+avro
producer:
useNativeEncoding: true
function:
definition: order;
bindings:
orderBuy-out-0.destination: order
kafka:
bootstrap-servers: localhost:9092
default:
producer:
configuration:
key.serializer: io.confluent.kafka.serializers.KafkaAvroSerializer
value.serializer: io.confluent.kafka.serializers.KafkaAvroSerializer
retry.backoff.ms: 100
schema.registry.url: http://localhost:8081
max.in.flight.requests.per.connection: 1
binder:
requiredAcks: all
Las propiedades a destacar del fichero anterior serán:
- spring.cloud.stream.function.definition: Esta propiedad tendrá el nombre del método que se encargará de enviar el evento.
- spring.cloud.stream.bindings.order-out-0.destination: Tendrá el nombre del topic al que se envía, la estructura es siempre la misma indicando. Out indica que es de salida.
- spring.cloud.schema.avro.dynamicSchemaGenerationEnabled: Esta propiedad definida a true nos permite subir el schema, al schema registry.
- spring.cloud.stream.kafka.default.producer.configuration.schema.registry.url: Indica la url del schema registry.
Consumidor
spring:
application:
name: service-management
cloud:
schema:
avro:
dynamicSchemaGenerationEnabled: true
stream:
default:
contentType: application/*+avro
consumer:
useNativeDecoding: true
function:
definition: orders
bindings:
orders-in-0:
contentType: application/*+avro
destination: order4
input:
content-type: avro/bytes
kafka:
bootstrap-servers: localhost:9092
binder:
requiredAcks: all
consumer-properties:
key.deserializer: io.confluent.kafka.serializers.KafkaAvroDeserializer
value.deserializer: io.confluent.kafka.serializers.KafkaAvroDeserializer
schema.registry.url: http://localhost:8081
specific.avro.reader: true
Generar un Schema con Avro
Nuestro ejemplo va a hacer uso de Avro para la generación de los objetos que van a ser enviados.
Los Schmeas en Avro utilizan la extensión avsc por lo que vamos a generar un fichero con esta extensión y añadir el siguiente json:
{
"type": "record",
"name": "Order",
"namespace": "com.refactorizando.example.schemaregistry.producer.message.avro",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "customerId",
"type": "string"
},
{
"name": "car",
"type":[
{
"type":"record",
"name":"Car",
"fields":[
{
"name":"id",
"type":"string"
},
{
"name":"model",
"type":"string"
},
{
"name":"brand",
"type":"string"
},
{
"name":"color",
"type":"string"
}
]
}
]
},
{
"name": "orderDate",
"type": {
"type": "int",
"logicalType": "date"
}
}
]
}
En nuestro fichero creado podemos ver que tenemos dos objetos, Order y Car que se encuentra dentro de Order. Este fichero generará dos objetos Java Order y Car, gracias al Plugin de Maven que hemos añadido en nuestro pom.xml. La ruta de lectura y escritura de los objetos habrá sido definida en el pom.xml.
Enviar un evento a Kafka con Spring Cloud Stream
Spring Cloud Stream nos va a permitir enviar eventos de manera constante, por lo que para ello es necesario crear un Bean que defina un método de tipo Supplier.
En nuestro ejemplo caso vamos a hacer uso del objeto Order para enviar 4 eventos haciendo uso de Message y Supplier:
@Bean
public Supplier<Message<Order>> order() {
return () -> {
if (order.peek() != null) {
Message<Order> o = MessageBuilder
.withPayload(order.peek())
.setHeader(KafkaHeaders.MESSAGE_KEY, Objects.requireNonNull(order.poll()).getId())
.build();
log.info("Order event sent: {}", o.getPayload());
return o;
} else {
return null;
}
};
}
Una vez hemos completado nuestro consumidor y lo ejecutamos, veremos que el schema que hemos generado haciendo uso de Avro se ha desplegado en nuestro Schema Registry y que se han envíado 4 eventos.
Consumir un Evento en Kafka con Spring Cloud Stream
Para realizar el consumo de los eventos que nos llegan desde Order vamos a utilizar la clase Consumer:
@Bean
public Consumer<Order> orders() {
return (order) -> log.info("Consumer Received : " + order.toString());
}
Una vez hemos creado nuestro consumidor y lo arrancamos podremos ver los mensajes consumidos (arrancar consumidor y productor en dos terminales diferentes).

Conclusión
En este ejemplo sobre Schema Registry con Kafka Stream y Avro en Spring Boot hemos visto como Spring Cloud Stream nos simplifica y nos ayuda en el tratamiento de eventos de Kafka Stream.
Si quieres descargar el ejemplo completo puedes hacerlo en Github.
Si necesitas más información puedes escribirnos un comentario o un correo electrónico a refactorizando.web@gmail.com o también nos puedes contactar por nuestras redes sociales Facebook o twitter y te ayudaremos encantados!