Procesamiento de Streams con Spring Cloud Data Flow

ejemplo-spring-cloud-data-flow
En este nuevo artículo vamos a ver un ejemplo de procesamiento de streams con Spring Cloud Data Flow. En el cual analizaremos su funcionamiento y su utilidad a través de mensajería con Kafka y programación funcional.
Spring Cloud Data Flow es un módulo perteneciente al stack de Spring para el procesamiento de datos, en stream o en batch, gracias a su integración con microservicios. Este módulo es cloud-native por lo que se va a desplegar sin problema en algún entorno cloud, actualmente tieneo soporte oficial para Kubernetes y Cloud Foundry. También admite despliegues en Local.
¿Qué es Spring Cloud Data Flow?
Tal y como hemos comentado Spring Cloud Data Flow es un módulo que pertenece al stack de Spring.
Spring Cloud Data Flow es un conjunto de herramientas para construir y ejecutar en tiempo real procesamiento de datos en pipelines mediante el establecimiento de un flujo de mensajes entre aplicaciones Spring Boot. Este sistema esta pensado e ideado para ser cloud-native por lo que puede ser ejecutado en diferentes entornos de cloud así como en local.
Podemos distinguir dos tipos al usar Spring Cloud Data Flow, el primer caso de uso es para aquellas aplicaciones que se mantienen a lo largo del tiempo, es decir, aplicaciones que requieren de un flujo constante de datos; y aplicaciones que comienzan y terminan en un corto período, aplicaciones batch. Por lo que atendiendo a esta clasificación tenemos Spring Cloud Data Flow Stream o Batch.
Entre otras características de Spring Cloud Data Flow nos ofrece:
- Aunque esta preparada para los entornos cloud, podemos probarla sin ningún problema en local, para ello podemos probar la integración con las aplicaciones a través de imágenes docker, o haciendo uso de maven para los artefactos.
- O podemos desplegar en entornos cloud para lo que facilita su despliegue en Kubernetes o Cloud Foundry.
- Dashboard o cliente para mostrarnos una interfaz con la que poder interactúar y verificar y comprobar el flujo.
- Nos va a facilitar la conexión con un servidor Oauth2.
- Además, gracias a que expone un API Rest, vamos a poder conectar algún sistema de integración continua, como podría ser Jenkins.
Arquitectura de Spring Cloud Data Flow
Como hemos comentado anteriormente podríamos dividir la arquitectura de spring cloud data flow en dos, procesos stream (procesos en tiempo real) y procesos batch/tasks (procesos que terminan y acaban en un corto período).
Procesamiento batch: Vamos a definir procesamiento batch como aquel proceso de que tiene una cantidad finita de información. Estas aplicaciones son consideradas efímeras o short-lived en inglés.
Procesamiento en Stream: Vamos a definir o a considerar un stream como una cantidad ilimitada de datos sin interrupción. Procesamiento en Stream con Spring Cloud Data Flow se encuentra implementado como una colección independiente de eventos conectados a través de un broker de mensajería.
En el siguiente diagrama podemos ver un alto nivel de su arquitectura:
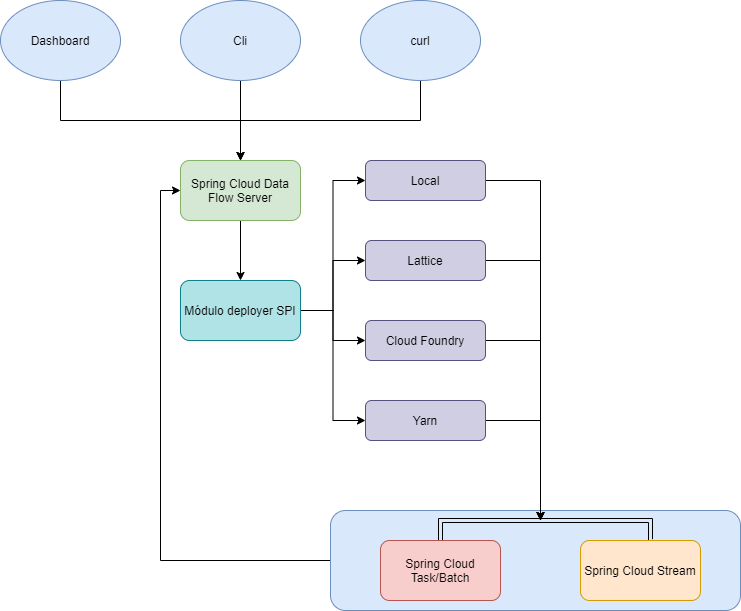
Spring Cloud Data Flow que se despliega como un microservicio más, el cual puedes descargartelo o ejecutarlo con Docker, nos va a proporcionar un API a través del cual podremos acceder con un Dashboard, curls o con un cliente.
Por otro lado tenemos el módulo de deployer SPI, el cual nos permitirá y habilitará diferentes despliegues o cloud o local.
Una vez tenemos todo ejecutado, arrancado y funcionando, los procesos así como su estado serán almacenado en la base de datos del Data Flow.

Cuando hacemos uso de Spring Cloud Stream, vamos a hacer uso de la siguiente arquitectura:
Source: Será el encargado de producir un mensaje.
Proccesor: Es el encargado de realizar un procesamiento en el mensaje.
Sink: Es el encargado de consumir un mensaje
Hands On con Spring Cloud Data Flow y Stream proccesing
Si quieres ir directamente al ejemplo puedes decargarlo desde aquí.
A continuación vamos a realizar un ejemplo con Spring Cloud Data Flow, en el que nos centraremos en la opción de streaming de datos. Nuestro ejemplo va a consistir en 3 microservicios que se comunican entre si. El caso consitirá en un Microservicio de producto de una tienda, un microservicio de procesado, y un microservicio de carrito al que le llegará un producto ya procesado.
- Productor: El producto enviará un mensaje al seleccionar el producto.
- Procesador: Si el producto tiene un precio mayor de 10€, se aplica un descuento del 10%.
- Consumidor: Producto seleccionado con el nuevo precio y almacenado en el carrito de compra.
Para ello vamos a dividir el proceso en varios pasos:
- Configuración servidor Data Flow con Docker
- Creación microservicio Productor
- Creación microservicio Consumidor
- Creación microservicio Procesador
El ejemplo será integramente desplegado en local.
Antes de comenzar vamos a levantar una imágen docker de kafka en nuestro local ya que nuestros servicios harán uso de ella:
docker run --rm -p 2181:2181 -p 3030:3030 -p 8081-8083:8081-8083 -p 9581-9585:9581-9585 -p 9092:9092 -e ADV_HOST=localhost landoop/fast-data-dev:latest
Arrancar Spring Cloud Data Flow con Docker Compose
A continuación vamos arrancar Spring Cloud Data Flow con Docker para ello, haciendo uso de la página de Spring, vamos a utilizar el docker-compose que nos proporcionan.
Antes hay que realizar la configuración de HOST_MOUNT_PATH y DOCKER_MOUNT_PATH a través de variables.
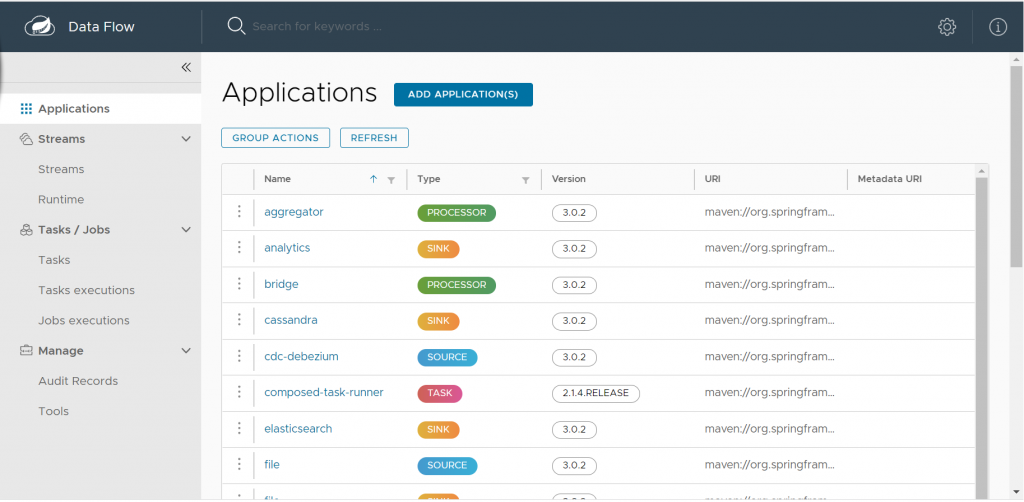
Para ver si se arrancó correctamente podemos ir al dashboard con la esta url: http://localhost:9393/dashboard
Al ejecutar la url deberíamos de ver algo así:
Arrancar Spring Cloud Data Flow manualmente
También podemos arrancar Spring Cloud Data Flow de manera manual ejecutando los jars.
Creación Microservicio Productor para Spring Cloud Data Flow
A continuación vamos a crear el microservicio Productor, el cual se encargará de seleccionar un producto. Para ello vamos a hacer uso de programación funcional y de spring-cloud-stream-binder-kafka para crear nuestro productor:
Por un lado vamos a crear la clase configuración que será la encargada de enviar un mensaje a kafka. Esta clase haciendo uso de la clase Supplier y Flux de la programación reactiva enviaremos un mensaje:
@Configuration
@Slf4j
public class KafkaConfiguration {
Random random = new Random();
static List<Product> productList = new ArrayList<>();
static {
productList.add(new Product(1L,"Milk", 1));
}
@Bean
public Supplier<Flux<Product>> sendProduct(){
return () -> Flux.interval(Duration.ofSeconds(5))
.map(value -> productList
.get((int)((Math.abs(productList.size() - 1)) * Math.random()))).log();
}
}
Por otro lado vamos a realizar a realizar la definición de nuestro binding y de nuestra función de stream en nuestro fichero de propiedades:
server:
port: 9001
spring:
cloud:
stream:
function:
definition: sendProduct;
bindings:
sendProduct-out-0:
destination: products
kafka:
binder:
brokers: localhost:9092
auto-create-topics: true
Una vez hemos configurado nuestro productor es momento de arrancarlo:
mvn spring-boot:run
Creación Microservicio Procesador
De la misma manera que hemos creado nuestro Productor, vamos a crear nuestro microservicios Processor. Este microservicio será el encargado de evaluar si a un producto se debe de aplicar un descuento.
Para que este microservicio procese los mensajes y aplique el descuento tiene que tener un precio mayor que 1.
Al igual que hemos hecho con el productor o source, vamos crear un método a través programación funcional, para ello haremos uso de Function de Java y Flux:
@Configuration
@Slf4j
public class KafkaConfiguration {
@Bean
public Function<Flux<Product>, Flux<Product>> productProcessor(){
return product -> product
.map(i -> evaluateProduct(i))
.log();
}
private Product evaluateProduct(Product product) {
if (product.getPrice() > 5) {
product.setPrice(product.getPrice()*0.10);
}
return product;
}
}
Hay que tener un cuenta que este servicio va a consumir y a producir productos, por lo que en su configuración tenemos que añadir tanto un consumidor como un productor. Veamos su application.yaml
server:
port: 9002
spring:
cloud:
stream:
function:
definition: productProcessor
bindings:
productProcessor-in-0:
destination: product
productProcessor-out-0:
destination: processed
kafka:
binder:
brokers: localhost:9092
auto-create-topics: true
Una vez configurado nuestro microservicio processor lo arrancamos como un servicio normal con:
mvn spring-boot:run
Creación Microservicio Consumidor para Spring Cloud Data Flow
A continuación vamos a crear nuestra última pieza en nuestra arquitectura de Spring Cloud Data Flow Stream, un microservicio Sink, es decir, la parte consumidora. Una vez nuestro producto ha sido procesado tenemos que crear un consumidor que se encarga de consumir ese mensaje.
Al igual que en los casos anteriores, haremos uso de programación funcional para consumir el mensaje. Para ello utilizaremos la clase Consumer para recibir un Product:
@Configuration
@Slf4j
public class KafkaConfiguration {
@Bean
public Consumer<Product> productConsumer(){
//Do something with product
return (product) -> log.info("Consumer Received : " + product);
}
}
Al igual que en los casos anteriores vamos a añadir la configuración en nuestro application.yaml
server:
port: 9003
spring:
cloud:
stream:
function:
definition: productConsumer;
bindings:
productConsumer-in-0:
destination: processed
kafka:
binder:
brokers: localhost:9092
auto-create-topics: true
Y al igual que en los casos anteriores arrancamos el servicio haciendo uso de maven:
mvn spring-boot:run
Registrar servicios en Spring Cloud Data Flow Server
Una vez tenemos todos los servicios arrancados y funcionando correctamente, es el momento de comenzar a registrar nuestras aplicaciones en Spring Cloud Data Flow.
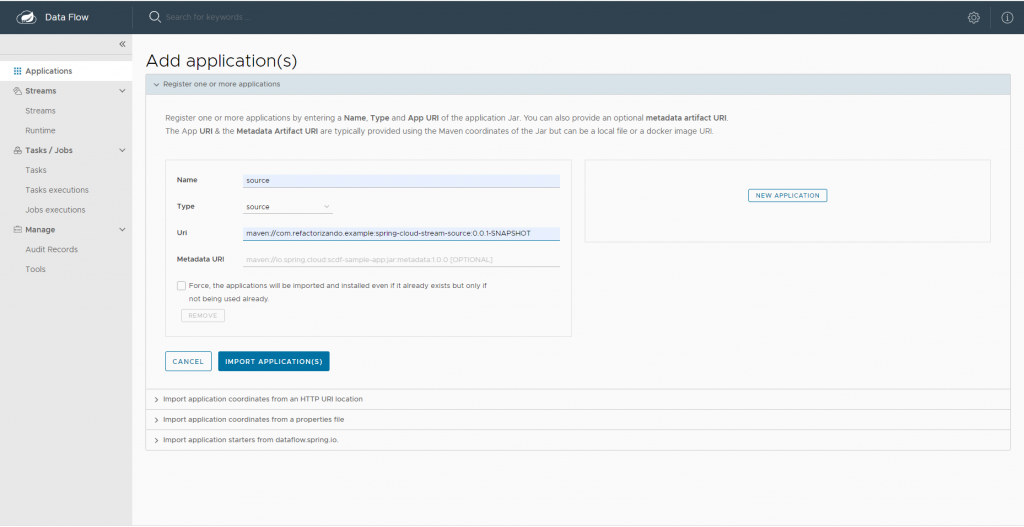
El primer paso para registrar la aplicación es pulsar sobre applications y add applications:

Y a continuación añadimos las aplicaciones en register one or more applications. En nuestro caso vamos a realizar este proceso 3 veces, para source, processor y sink.
La uri tiene que ir específicada como group-id, artifact-id y versión. Por ejemplo: maven://com.refactorizando.example:spring-cloud-stream-source:0.0.1-SNAPSHOT
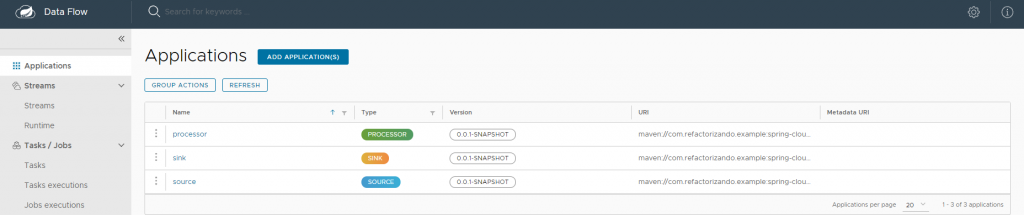
Una vez hemos registrado nuestras 3 aplicaciones deberíamos ver algo así:
Creación de Stream
Una vez tenemos nuestras tres aplicaciones registradas en el servidor es momento de crear el Stream para este ejemplo de Procesamiento de Streams con Spring Cloud Data Flow . Para poder crear un Stream en el Dashboard de Spring Cloud Data Flow, pulsaremos sobre Streams y Create Stream.
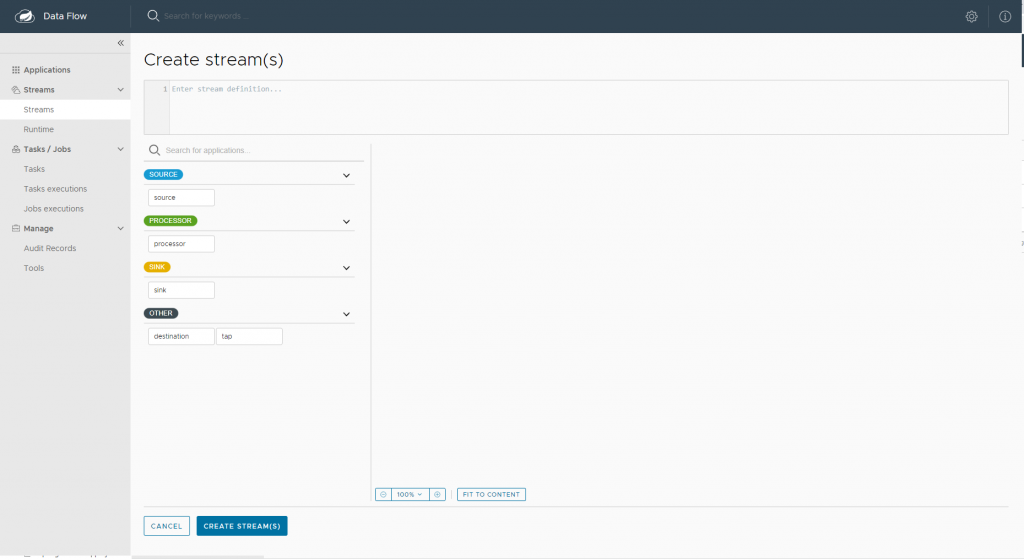
En esta pantalla arastraremos las aplicaciones y las conectaremos entre sí formando el flujo correcto. Para formar el flujo vamos a escribir en «Enter Stream Definition» cada aplicación y después la podremos conectar.
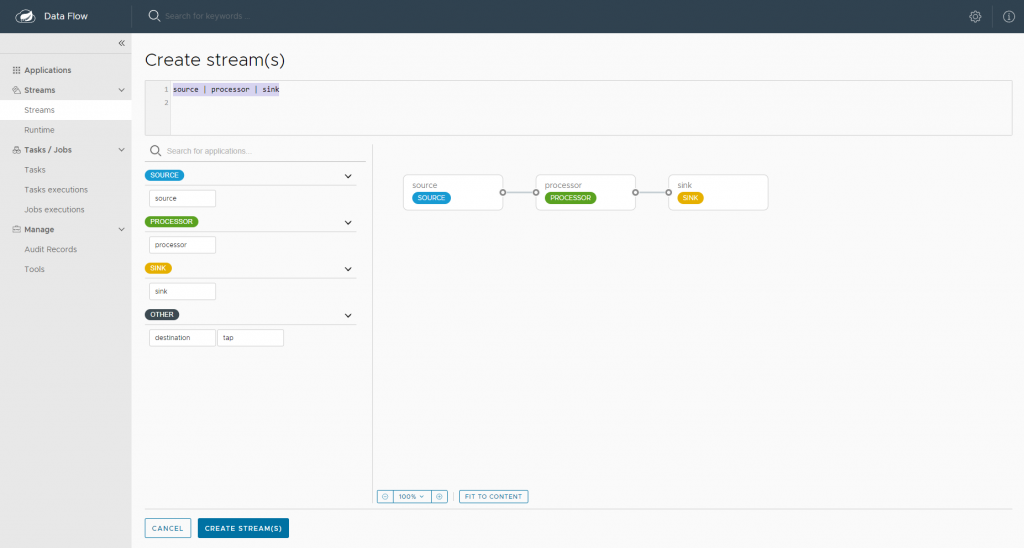
Una vez creado lo guardamos y pulsamos sobre deploy para generarlo.
Esta herramienta nos ayudará en nuestra arquitectura de microservicios a ser capaces de ver porque puede fallar la comunicación y la arquitectura. Con el ejemplo anterior vamos a poder ver de manera constante los logs de cada microservicios, gracias a lo cual, vamos a poder tener información en tiempo real de lo que esta pasando para intentar solucionar algún problema.
CI y CD con Spring Cloud Data Flow
Básicamente cualquier arquitectura de microservicios tendrá un sistema de CI/CD para poder realizar integración y despliegues continuos, y así tener integrado a través de una herramienta todas las partes involucradas.
Spring Cloud Data Flow nos va a permitir integrar este proceso en nuestro pipeline para poder tener un proceso totalmente automático. Aunque como hemos visto el proceso puede ser manual, es algo que siempre que se pueda hay que evitarlo.
El servidor de Spring Cloud Data Flow, nos va a proporcionar un API para poder integrarnos con el y a través de un servidor de integración continua poder realizar los despliegues de nuestros servicios. Esta API deberá de estar correctamente securizada con nuestro servidor para poder realizar este proceso.
Con este proceso, podríamos automatizar cada build en el entorno correspondiente con su versión correcta, y así evitar cualquier proceso manual.
Conclusión
En este ejemplo de Procesamiento de Streams con Spring Cloud Data Flow hemos podido ver una introducción a lo que este modulo nos puede ofrecer.
Este artículo nos ha ayudado para ver una pequeña introducción y ver lo que Spring Cloud Data Flow nos puede ofrecer, así como sus integraciones con diferentes componentes e infraestructuras como autenticación y herramientas de CI/CD.
Si quieres ver el código del ejemplo completo lo puedes descargar desde nuestro github.
Si necesitas más información puedes escribirnos un comentario o un correo electrónico a refactorizando.web@gmail.com o también nos puedes contactar por nuestras redes sociales Facebook o twitter y te ayudaremos encantados!