Observabilidad en una Arquitectura de Microservicios

monitoring
Actualmente uno de los paradigmas que más fuerza y más se utiliza es el desarrollo o las arquitecturas orientadas a Microservicios. Al igual que han surgido diferentes patrones de diseño para poder implementar y llevar a cabo una arquitectura orientada a microservicios y al cloud. También han surgido patrones para poder saber si todo nuestro desarrollo esta funcionando como debería. En esta nueva entrada de Observabilidad en una arquitectura de microservicios, vamos a comentar tres patrones orientados al cloud y a los microservicios: monitoring, logging y alertas.
Monitoring
Las arquitecturas de microservicios pueden llegar a crecer a gran velocidad, por eso necesitamos saber que todo esta funcionando correctamente. O no solo si fallan, también hay que saber si nuestro sistema se esta degradando o si por ejemplo no somo capaces de cumplir unas SLA’s (Service Level Agreement). La monitorización de nuestro sistema va a estar proporcionado métricas y valores de forma constante para analizar el correcto funcionamiento.
¿Qué hacer con los datos de la monitorización?
Nuestros sistemas van a proporcionar una gran cantidad de datos, que de alguna manera vamos a tener que procesar y entender. Por ejemplo si nuestro sistema es sobre pago de impuestos, y el comportamiento normal es el procesamiento de 5000 pago de impuestos por hora, y de repente tenemos 100, podríamos intuir que hay algún problema.
En estos casos podríamos tener métricas de la plataforma sobre los tiempos promedios, los más lentos y lo más rápidos en los que se han realizado peticiones a base de datos; o los procesamientos que han empezado y acabado correctamente.
Estas métricas, por ejemplo, se podrán explotar en algún dashboard, que nos ayudará a entender a bajo nivel el rendimiento y el comportamiento de nuestra infraestructura. Estas métricas nos ayudaran a saber si el sistema o el rendimiento se esta degradando y puede hacer que el sistema falle. Es importante usar datos a bajo nivel para que nos ayuden a prevenir cualquier fallo antes de que ocurra.
Logging
El logging es uno de los factores importantes en Observabilidad en una Arquitectura de Microservicios. Cualquier lenguaje de programación nos va a permitir escribir logging para conocer por donde pasa nuestra aplicación. Por lo general, además, estas librerías permiten escribir diferentes niveles de log, por ejemplo: WARN, INFO, DEBUG, ERROR.
Estos diferenetes niveles de log nos va a permitir, diferente granularidad a la hora de trazar cualquier error en nuestro sistema. Si tenemos activado el nivel de traza a error, solo nos sacará aquellos mensajes en lo que se haya podido producir algún error en nuestro sistema, por ejemplo, en aquellos puntos en los que se devuelva una excepción. Por lo general se «jugará» con los diferentes niveles de log para obtener errores, o para poder hacer debug de la aplicación.
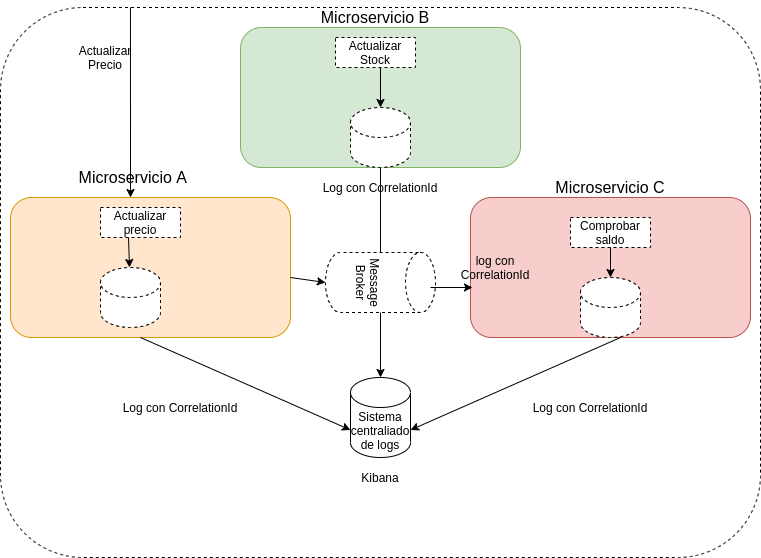
Debido al uso de clouds y arquitecturas orientadas a microservicios, se busca un sistema de logging centralizado, en el que todos los logs de los diferentes microservicios o partes de tu sistema puedan ser consultados o explotados en un único sitio. Algunos ejemplos de sistemas para explotar logs puede ser kibana, una herramienta de elastic que nos va ayudar a monitorizar y obtener información en tiempo real.
Trazabilidad en logs
Con una arquitectura orientada a microservicios va a ser muy importante tener un seguimiento de las llamadas entre nuestros servicios, y poder saber quién y desde dónde ha podido ser invocado. Para ello se suele añadir un Correlation ID, el cuál es un identificador, que nos permitirá obtener todos los mensajes relacionado de una invocación a nuestro servicio.
Existen diferentes iniciativas sobre la correlación entre los microservicios como la libería Spring Cloud Sleuth que nos va a permitir obtener esta correlación entre los microservicios, la cual esta basada en Zipking.
Alertas
En un sistema en el que cada parte funciona como un engranaje con otra parte, es necesario e imprescindible tener un sistema de alertas.
Las alertas deben ser sistemas que nos adviertan de que algo esta fallando o va mal. Se pueden crear alertas, por ejemplo, que avisen cuando se devuelve un status code 500, lo que nos indicará que nuestro servidor da un error interno. Cuando se detecta un error, se deberá de enviar un aviso a aquellos responsables de la monitorización o propietarios del sistema para que investiguen que ha podido pasar. Para poder investigar se hará uso de las piezas vistas anteriormente.
¿Pero qué pasará si nuestro sistema de detención esta configurado a un bajo nivel y envía una alerta constantemente?; en estos casos, será muy complicado detectar la fuente del problema. Por lo que, de manera general, es mejor establecer un umbral de error calculando un promedio de errores. Es decir, si establecemos que por cada error 500 se envíe una alerta, se podrían llegar a recibir un número de alertas demasiado alto, que perjudicaría en la detención final del error.
Conclusión
En esta entrada, hemos visto tres patrones que habría que seguir sobre Observabilidad en una Arquitectura de Microservicios. Actualmente y con nuestras aplicaciones o sistemas orientados al cloud y a los microservicios se hace cada vez más importante tener un buen sistema de observabilidad establecido.
Espero que este artículo haya sido de utilidad si tienes alguna duda o sugerencia no dudes en comentarlo o contactar a través de Facebook o Twitter. Y si te ha gustado compártelo en tus redes sociales.
fdsfadsa