Introducción y ejemplo a Elasticsearch en Spring Boot

Ejemplo Spring Boot con Elasticsearch
En esta entrada vamos a ver una introducción y ejemplo a Elasticsearch en Spring Boot para realizar una conexión y operaciones contra esta base de datos no relacional.
Veremos de manera sencilla y eficaz como indexar, buscar y realizar queries contra Elasticsearch haciendo uso de Spring Data.
Si quieres ir directo al ejemplo puedes ir hacia la sección Ejemplo de aplicación de Spring Data con Elasticsearch.
¿Qué es Elasticsearch?
Elasticsearch es un motor de búsqueda basado en Lucene. Elasticsearch se cataloga dentro de una base de datos no relacional y entre sus principales características se encuentran:
- Es distribuido.
- Multitenant y permite búsquedas completas de testo en documentos JSON.
- Tienen un schema libre, es decir, no hay estructura rígida de documento.
- Desarrollado en Java.
- Escalabilidad horizontal.
- Interfaz HTTP para interactuar con el cluster.
- Tiene «dos modos» index y search, es decir, o indexamos datos o buscamos.
Elasticsearch es muy utilizado en el mundo BigData por su velocidad de respuesta y las posibilidades de búsqueda que ofrece.
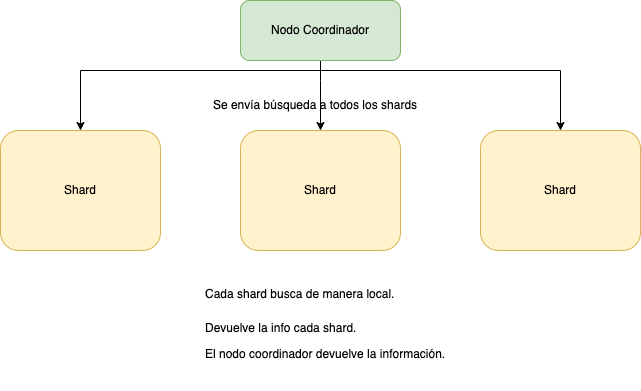
La arquitectura de Elasticsearch se basa en shards, lo que nos permite tener subconjunto de datos por shard, de manera que por un lado tenemos los shard primarios que se encargan de indexar, y por otro lado los shard réplicas que van replicar la información en función de los shard primarios.
Conceptos e introducción a Elasticsearch
Antes de meternos en faena y ver un ejemplo vamos a ver algún concepto sobre Elasticsearch.
En Elasticsearch vamos a diferenciar dos acciones, búsquedas e indexaciones. Cualquier búsqueda que se realice ha tenido que ser previamente guardado en forma de documento en un índice.
El texto que guardamos en un índice, es previamente es procesado por varios analizadores. El analizador por defecto separa las palabras de una frase, es decir, si tenemos la frase: Hola qué tal, se separaría en términos por «hola» «qué» «tal».
Campos multicampos y meta-campos
Los campos en Elasticsearch son la unidad más pequeña de información. Por ejemplo name, surname, birth….
Cada campo define tipos que pueden ser:
- simples: string, number, date etc.
- complejos: Objetos y objetos anidados.
- geo: son datos de tipo geográfico como get_point y geo_shape.
- especializados: datos de tipo token count, dense vector, join etc…
Los multicampos o multifields en Elasticsearch, a diferencia de los campos sencillos, son aquellos que pueden ser utilizados para obtener más resultados de búsqueda.
Finalmente los meta-fields o meta-campos en Elasticsearch trata con la información meta data de un documento.
Documentos en Elasticsearch
Los documentos en Elasticsearch es la manera en la que vamos a indexar la información en formato JSON.
Los documentos contienen palabras reservadas como _index, _type o _id.
{
"_id": 3,
“_type”: "external",
“_index”: "car_index",
"_source":{
"color": ["yellow"],
"name": ["mustang”],
"year":2002
....
}
}
Mapping en Elasticsearch
Un mapping en Elasticsearch es la representación de los datos en el índice, lo podríamos comparar con el schema en una base de datos relacional.
El mapeo define los diferentes tipos dentro de un índice (hay que tener en cuenta que desde la versión 7 solo puede existir un tipo dentro de un índice)
Shards
Un shard es un índice en Lucene. Podemos definirlo como bloques de información en Elasticsearch que va a facilitar su escalabilidad.
Los shards nos ayudarán a dividir la información y evitar problemas de dimensionamiento en un índice. Los shard puede ser configurado a través del API de Elasticsearch:
curl -XPUT localhost:9200/workshop -d '{
"settings" : {
"index" : {
"number_of_shards" : 4,
"number_of_replicas" : 2
}
}
}'
Réplicas
Las réplicas en Elasticsearch junto con los shards nos va a ayudar a tener un sistema más resiliente. Las réplicas van a tener una doble función para mejorar el rendimiento de búsqueda y como back up por si tenemos un nodo caído.
Al igual que los shards los podemos definir a través del API de Elasticsearch.
Analizadores
Los analizadores en Elasticsearch tal y como la palabra indica, se utilizan para «analizar» frases y expresiones.
Un analizador consta de un tokenizador y filtros.
Después de estos conceptos estamos preparados para empezar con un ejemplo de Elasticsearch en Spring Boot.
Dependencia de Elasticsearch con Spring Boot
Como ya hemos visto en otros ejemplos, Spring Data nos va a ayudar a eliminar el boilerplate que se necesita para interactuar con una Base de Datos. Para poder trabajar con elasticsearch en nuestra aplicación Spring Boot será suficiente con añadir la siguiente dependencia:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
Si en un lugar de usar Spring Data queremos usar los propios conectores de Elasticsearch podemos utilizar las siguientes dependencias:
El conector de Elasticsearch de alto nivel que da muchas propiedades que no tiene Spring Data:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${version}</version>
</dependency>
Y el conector de bajo nivel que permite una mayor personalización:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>${version}</version>
</dependency>
Configuración de Elasticsearch con Spring Boot
Spring Data Elasticsearch utiliza Java High Level REST Client (JHLC) para conectarse a un servidor de Elasticsearch.
Para realizar la configuración y conexión a Elasticsearch podemos hacerlo a través de los ficheros de propiedades o configurando el bean de Spring Data Elasticsearch a mano:
spring.elasticsearch.rest.uris=localhost:9200 spring.elasticsearch.rest.connection-timeout=1s spring.elasticsearch.rest.read-timeout=1m spring.elasticsearch.rest.password= spring.elasticsearch.rest.username=
La manera alternativa para configurarlo puede ser creando un Bean de tipo AbstractElasticsearchConfiguration:
@Configuration
@RequiredArgsConstructor
public class ElasticsearchConfiguration extends AbstractElasticsearchConfiguration {
private final ElasticsearchProperties elasticsearchProperties;
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo(elasticsearchProperties.getHostAndPort())
.withSocketTimeout(elasticsearchProperties.getSocketTimeout())
.build();
return RestClients.create(clientConfiguration).rest();
}
}
Con estas configuraciones hemos conseguido conectar nuestra aplicación a un servidor de Elasticsearch, la conexión anterior es una configuración básica, podemos añadir timeout de conexión, SSL etc…
Creando un documento en Spring Data para Elasticsearch
A continuación vamos a crear un Documento a través de la anotación @Document para realizar la representación de un objeto en nuestro índice de Elasticsearch.
@AllArgsConstructor
@NoArgsConstructor
@Getter
@Setter
@Document(indexName = "user")
public class User {
@Id
private String id;
@Field(type = FieldType.Text, name = "name")
private String name;
@Field(type = FieldType.Text, name = "surname")
private String surname;
@Field(type = FieldType.Date, name = "birth")
private Date birth;
@Field(type = FieldType.Integer, name = "child")
private Integer child;
@Field(type = FieldType.Keyword, name = "sex")
private String sex;
public enum Sex {
MALE,
FEMALE,
OTHER;
}
}
Vamos a explicar los puntos importantes de la clase anterior definida:
- @Document, específica el nombre del índice.
- @Id es el _id de nuestro documento, será el único identificador.
- @Field configura el tipo de un campo.
El índice user será creado con estos campos.
Para aplicar y ver esta configuración podemos arrancar nuestra aplicación y dejar a Spring Data que haga su magia. Una vez arrancada la aplicación podemos hacer un curl al servidor de Elasticsearch directamente para ver el settings:
curl --request GET \ --url http://localhost:9200/user/_settings
o si queremos ver los mappings:
curl --request GET \ --url http://localhost:9200/user/_mappings
Creación de Repository en Spring Data con Elasticsearch
A continuación vamos a crear la capa Repository de nuestro proyecto, para ello extenderemos de ElasticsearchRepository.
public interface UserRepository extends ElasticsearchRepository<User, String> {
User findByName(String name);
}
La clase ElasticsearchRepository nos proporcionará los métodos básicos para realizar operaciones sobre el índice. Además hemos creado tres métodos más a partir de la nomenclatura que nos proporciona Spring Data para realizar búsquedas.
Una vez hemos creado la clase UserRepository, podemos hacer uso de esta clase para invocar desde un servicio y poder realizar operaciones sobre el índice.
public class UserRepositoryService {
private final UserRepository userRepository;
public void createUserIndexBulk(final List<User> users) {
userRepository.saveAll(users);
}
public void createUserIndex(final User user) {
userRepository.save(user);
}
public List<User> findUsers() {
return StreamSupport.stream(
Spliterators.spliteratorUnknownSize(userRepository.findAll().iterator(), 0), false)
.collect(Collectors.toList());
}
public User findUserByName(String name) {
return userRepository.findByName(name);
}
}
La clase anterior nos proporciona una clase de abstración sobre el repositorio creado anteriormente para poder operar sobre el índice.
Queries propias con @Query en Spring Data Elasticsearch
Al igual que con otras bases de datos, Spring Data nos proporciona la anotación @Query, para realizar búsquedas:
public interface UserRepository extends ElasticsearchRepository<User, String> {
List<User> findAllByName(String name);
@Query("{\"match\":{\"name\":\"?0\"}}")
List<User> findAllByNombreUsingAnnotations(String name);
}
Uso de ElasticsearchRestTemplate para indexaciones y búsquedas
Spring Data es perfecto para una primera aproximación o cuando el nivel que se tiene en Elasticsearch no es muy alto y delegamos en Spring Data las operaciones. Pero para aquellas situaciones en las que necesitamos más control sobre las queries o el equipo tiene mucho dominio en Elasticsearch es mejor hacer uso de ElasticsearchRestTemplate.
Este es el cliente de Elasticsearch basado en HTTP que sustituye al TransportClient de versiones anteriores.
ElasticsearchRestTemplate implementa ElasticsearchOperations.
Búsquedas con ElasticsearchRestTemplate
ElasticsearchRestTemplate nos va a permitir realizar búsquedas sobre nuestro índice de tres maneras diferentes, NativeQuery, StringQuery o CriteriaQuery.
Búsquedas con NativeQuery
Las búsquedas por NativeQuery en Elasticsearch haciendo uso de ElasticsearchRestTemplate nos proporciona la máxima flexibilidad para construir una query.
public void findCarsByModel(final String model) {
QueryBuilder queryBuilder =
QueryBuilders
.matchQuery("mustang", model);
Query searchQuery = new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.build();
SearchHits<Car> carHits =
elasticsearchOperations
.search(searchQuery,
Car.class,
IndexCoordinates.of(INDEX));
}
}
Búsquedas con StringQuery
El uso de StringQuery nos da control total permitiendo el uso nativo de queries con Elasticsearch como JSON:
public void findCarByName(String name) {
Query searchQuery = new StringQuery(
"{\"match\":{\"name\":{\"query\":\""+ name + "\"}}}\"");
SearchHits<Car> cars = elasticsearchOperations.search(
searchQuery,
Car.class,
IndexCoordinates.of(INDEX));
}
Búsquedas con CriteriaQuery
Las búsquedas por CriteriaQuery que nos proporciona ElasticsearchRestTemplate, nos va a permitir realizar búsquedas sin tener conocimientos muy amplios de Elasticsearch:
public void findCarByColor(String color) {
Criteria criteria = new Criteria("color")
.equals("yellow");
Query searchQuery = new CriteriaQuery(criteria);
SearchHits<Car> cars = elasticsearchOperations
.search(searchQuery,
Car.class,
IndexCoordinates.of(INDEX));
}
Indexaciones con ElasticsearchRestTemplate
Para realizar indexaciones podemos realizarla a través de bulk (inserción de muchos documentos) o realizando inserciones de un único documento.
Por ejemplo para realizar una inserción en bulk con ElasticsearchRestTemplate podemos hacer:
@Service
@Slf4j
@RequiredArgsConstructor
public class UserRestTemplateService {
private static final String INDEX = "user";
private final ElasticsearchOperations elasticsearchOperations;
public List<String> createUserIndexBulk(final List<User> users) {
List<IndexQuery> queries = users.stream()
.map(user->
new IndexQueryBuilder()
.withId(user.getId().toString())
.withObject(user).build())
.collect(Collectors.toList());;
return elasticsearchOperations.bulkIndex(queries, IndexCoordinates.of(INDEX))
.stream()
.map(object->object.getId())
.collect(Collectors.toList());
}
o si solo queremos insertar un documento:
@Service
@Slf4j
@RequiredArgsConstructor
public class UserRestTemplateService {
private static final String INDEX = "user";
private final ElasticsearchOperations elasticsearchOperations;
public String createUserIndex(User user) {
IndexQuery indexQuery = new IndexQueryBuilder()
.withId(user.getId().toString())
.withObject(user).build();
String documentId = elasticsearchOperations.index(indexQuery, IndexCoordinates.of(INDEX));
return documentId;
}
}
Ejemplo de aplicación de Spring Data con Elasticsearch
Para seguir con nuestra introducción y ejemplo a Elasticsearch en Spring Boot vamos a codificar un sencillo ejemplo haciendo uso de algunos de los conceptos que hemos explicado anteriormente.
Si quieres acceder directamente al ejemplo lo puedes hacer en el github de refactorizando.
Para crear la aplicación vamos a ir paso por paso viendo todo el proceso, para ello vamos a ir Spring Initializr y nos dará un pom.xml con las dependencias necesarias para poder crear la aplicación.
En la aplicación que vamos haremos uso de ElasticsearchRestTemplate y de un Repositorio creado con Spring Data.
Para popular el índice de Elasticsearch con objetos de tipo User vamos a cargar un fichero CSV.
Antes de empezar será necesario arrancar un servidor de Elasticsearch, en nuestro caso vamos a hacer uso de la versión 7.X.X
Servidor de Elasticsearch con Docker
El siguiente comando ejecutando en tu terminal te levantará la versión 7.10.0 con lo que podrás realizar el ejemplo que exponemos a continuación:
docker run -p 9200:9200 \ -e "discovery.type=single-node" \ docker.elastic.co/elasticsearch/elasticsearch:7.10.0
Dependencias Maven con Elasticsearch
Las dependencias imprescindibles para poder crear una aplicación con Elasticsearch haciendo uso de Spring Data son:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency>
Con las dependencias anteriores tendremos lo suficiente para crear una aplicación que inserte y busque datos.
Ya hemos comentado que podemos añadir las librerías de High y Rest pero ahora no lo abordaremos.
Configuración de Elasticsearch en Spring Boot
Para realizar la conexión con Elasticsearch vamos a realizarlo a través de los ficheros de propiedades:
spring.elasticsearch.rest.uris=localhost:9200 spring.elasticsearch.rest.connection-timeout=1s spring.elasticsearch.rest.read-timeout=1m spring.elasticsearch.rest.password= spring.elasticsearch.rest.username=
Creación de Repositorio con Spring Data y Elasticsearch
Como hemos comentado anteriormente vamos a crear un repositorio que extiende de ElasticsearchRepository y además vamos a crear un método para buscar por nombre haciendo uso del naming de Spring Boot.
public interface UserRepository extends ElasticsearchRepository<User, String> {
User findByName(String name);
}
El anterior repositorio nos va a permitir hacer uso de los métodos de inserción y búsqueda definidos por defecto con Spring Data.
A continuación vamos a crear una capa Servicio que invocará a este repositorio.
Creación de Servicio para invocar a Repository
A continuación vamos a crear un Service que hará una invocación directa al Repositorio que hemos creado:
public class UserRepositoryService {
private final UserRepository userRepository;
public void createUserIndexBulk(final List<User> users) {
userRepository.saveAll(users);
}
public void createUserIndex(final User user) {
userRepository.save(user);
}
public List<User> findUsers() {
return StreamSupport.stream(
Spliterators.spliteratorUnknownSize(userRepository.findAll().iterator(), 0), false)
.collect(Collectors.toList());
}
public User findUserByName(String name) {
return userRepository.findByName(name);
}
}
Esta capa llamará directamente al Repositorio devolviendo la información de User. Como se puede ver para indexar y para obtener todos los usuarios lo hacemos a través de los métodos definidos por Spring Data, y para obtener un usuario por su nombre el método que hemos definido.
Creación de Servicio haciendo uso de ElasticsearchRestTemplate
Como hemos comentado anteriormente, Spring nos proporciona ElasticsearchOperations para poder realizar operaciones y tener más flexibilidad sobre nuestros índices de Elasticsearch.
Para ello vamos a realizar una serie de búsquedas e indexaciones sobre el índice user.
Vamos a realizar insercciones en bulk, inserciones de un único user y tres tipos de búsqueda por NativeQuery, Criteria y StringQuery:
@Service
@Slf4j
@RequiredArgsConstructor
public class UserRestTemplateService {
private static final String INDEX = "user";
private final ElasticsearchOperations elasticsearchOperations;
public List<String> createUserIndexBulk(final List<User> users) {
List<IndexQuery> queries = users.stream()
.map(user->
new IndexQueryBuilder()
.withId(user.getId().toString())
.withObject(user).build())
.collect(Collectors.toList());;
return elasticsearchOperations.bulkIndex(queries, IndexCoordinates.of(INDEX))
.stream()
.map(object->object.getId())
.collect(Collectors.toList());
}
public String createUserIndex(User user) {
IndexQuery indexQuery = new IndexQueryBuilder()
.withId(user.getId().toString())
.withObject(user).build();
String documentId = elasticsearchOperations.index(indexQuery, IndexCoordinates.of(INDEX));
return documentId;
}
public List<User> findUserByName(final String name) {
QueryBuilder queryBuilder = QueryBuilders.matchQuery("name", name);
Query searchQuery = new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.build();
SearchHits<User> hits = elasticsearchOperations.search(searchQuery, User.class, IndexCoordinates.of(INDEX));
return hits.stream()
.map(hit->hit.getContent())
.collect(Collectors.toList());
}
public List<User> findBySurname(final String surname) {
Query searchQuery = new StringQuery(
"{\"match\":{\"surname\":{\"query\":\""+ surname + "\"}}}\"");
SearchHits<User> users = elasticsearchOperations.search(
searchQuery,
User.class,
IndexCoordinates.of(INDEX));
return users.stream()
.map(hit->hit.getContent())
.collect(Collectors.toList());
}
public List<User> findByUser(final String user) {
Criteria criteria = new Criteria("name")
.greaterThan(10.0)
.lessThan(100.0);
Query searchQuery = new CriteriaQuery(criteria);
SearchHits<User> users = elasticsearchOperations
.search(searchQuery,
User.class,
IndexCoordinates.of(INDEX));
return users.stream()
.map(hit->hit.getContent())
.collect(Collectors.toList());
}
public List<User> processSearch(final String query) {
log.info("Search with query {}", query);
QueryBuilder queryBuilder =
QueryBuilders
.multiMatchQuery(query, "name", "surname")
.fuzziness(Fuzziness.AUTO); //crea todas las posibles variaciones
Query searchQuery = new NativeSearchQueryBuilder()
.withFilter(queryBuilder)
.build();
SearchHits<User> users =
elasticsearchOperations
.search(searchQuery, User.class,
IndexCoordinates.of(INDEX));
return users.stream()
.map(hit->hit.getContent())
.collect(Collectors.toList());
}
}
La clase anterior nos va a proporcionar todos los métodos que necesitamos para ver en funcionamiento el uso de las diferentes formas en las que podemos hacer búsquedas en un índice de Elasticsearch con ElasticSearchOperations.
Crear controlador
Como toda aplicación que se precie vamos a necesitar un API para tener un punto de acceso y de salida para ello haremos el siguiente controlador:
@RestController
@RequestMapping("/users")
@Slf4j
@AllArgsConstructor
public class UserController {
private final UserRestTemplateService userRestTemplateService;
@GetMapping()
@ResponseBody
public List<User> fetchByName(@RequestParam(value = "name", required = false) String name) {
log.info("searching by name {}",name);
List<User> users = userRestTemplateService.findUserByName(name) ;
log.info("users {}",users);
return users;
}
@GetMapping("/query")
@ResponseBody
public List<User> fetchByNameOrDesc(@RequestParam(value = "q", required = false) String query) {
log.info("searching by name {}",query);
List<User> users = userRestTemplateService.processSearch(query) ;
log.info("users {}",users);
return users;
}
}
ahora si invocamos a las siguientes urls:
http://localhost:8080/users/query?q=noel
Obtendremos la información que se solicita.
Conclusión
En esta entrada hemos visto una introducción y ejemplo a Elasticsearch en Spring Boot en las que hemos visto los conceptos básicos de Elasticsearch así como un ejemplo completo haciendo uso de Spring Data para acceder a un Índice de Elasticsearch.
Si quieres echar un ojo al ejemplo que hemos creado lo puedes hacer en nuestro github.
Si necesitas más información puedes escribirnos un comentario o un correo electrónico a refactorizando.web@gmail.com o también nos puedes contactar por nuestras redes sociales Facebook o twitter y te ayudaremos encantados!