Gobierno de Eventos con Schema Registry y Avro

schema-registry-avro
En arquitecturas orientadas a microservicios es cada vez más común el uso de eventos para la comunicación, siendo Kafka uno de los mayores exponentes en este tipo de comunicación o arquitecturas con eventos. Para estos casos, en los que nuestras arquitecturas van a hacer uso de eventos vamos a ver el siguiente artículo sobre Gobierno de Eventos con Schema Registry y Avro.
¿Qué es el Schema Registry de Kafka?
Schema Registry es una capa que nos ofrece almacenamiento de nuestros esquemas de eventos. Esta capa se encuentra fuera de nuestro clúster de kafka, y se encarga de la gestión y distribución de los esquemas entre el productor y el consumidor.
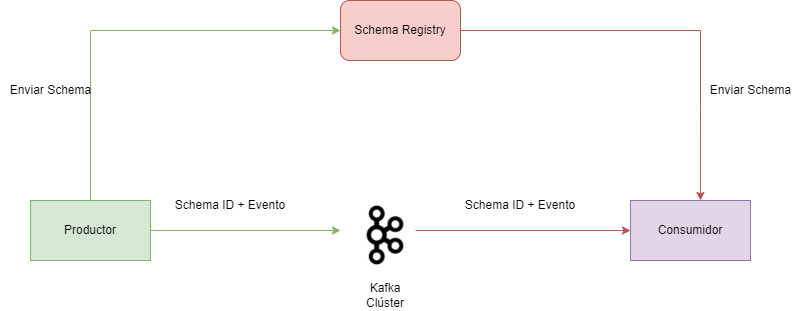
Cuando trabajamos con arquitecturas de streaming de datos, es muy importante dar algunas garantías sobre los datos que se van a enviar. Kafka no se encarga de procesar la información que recibe y envía, únicamente toma la información que le llega y la publica a los consumidores, por lo que no tenemos ninguna garantía de que el evento que el consumidor va a procesar es el correcto.
Una de las ventajas de Kafka es su velocidad de recepción y envío, por lo que no existe procesamiento del evento en el broker, ya que si esto se hiciese incurriría en un aumento de gasto de los recursos hardware, o ¿qué ocurre si un evento no tiene el formato esperado por el consumidor?, pues en ese caso es probable que suceda un error porque el consumidor no sea capaz de procesar el mensaje.
Para mitigar los problemas de los casos que hemos comentado anteriormente hacemos uso de Schema Registry en Kafka. Entre las principales características que podemos encontrar de hacer uso de un Schema Registry se encuentran algunas como:
- Tener un schema que tanto el consumidor y productor entienden y pueden procesar.
- Una copia es almacenada y cacheada por lo que los tiempos de consulta del schema son muy buenos.
- Los Schemas pueden cambiar en el tiempo, por lo que podemos utilizar versiones para ello.
- El consumidor estará alineado con el productor y el formato del mensaje, por lo que se evitarán los problemas de lectura de un mensaje.
Aunque para validar que no existen cambios entre los mensajes del productor y consumidor se pueden utilizar otras estrategias como Consumer Driven Contracts, aunque es una aproximación totalmente diferente. Schema Registry nos aporta más funcionalidades que únicamente la validez de contratos.
¿Cómo funciona el Schema Registry?
Schema Registry va a convivir dentro de nuestra infraestructura pero separado de Kafka y su función será la de almacén de schemas de nuestros mensajes.
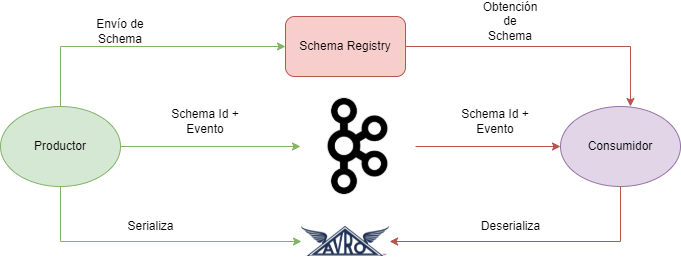
Al hacer uso de Schema Registry, el productor antes de enviar el mensaje a Kafka, se comunica primero con el schema Registry y verifica que el schema esta disponible. En el caso en el que el schema que se quiera enviar no se encuentre guardado este se cachea. Una vez el productor ya tiene el schema, se serializa la información con el schema y se envía a kafka en un formato binario y con un ID de schema. Cuando el mensaje llegar al consumidor, esté se comunica con el Schema Registry con el ID del schema y obtiene el schema para deserializarlo. En el caso de error se envía un error indicando se ha roto el contrato o schema.
Como hemos comentado, nuestro consumidor y productor harán uso del Schema Registry para serializar y deserializar nuestros mensajes. Vamos a ver los diferentes tipos que nos podemos encontrar.
Serialización con Schema Registry
Uno de los puntos más importantes a la hora de utilizar Schema Registry es la serialización y deserialización de los mensajes que envíamos. Para este punto deberemos ver si soporta un schema y si la información puede ser tratada como binaria. A continuación mostramos una tabla con los más comunes:
| Binary | Schema | |
| AVRO | Sí | Sí |
| Protocol Buffer | Sí | Sí |
| Thrift | Sí | Sí |
| YAML | No | No |
| XML | No | No |
| Json | No | Sí |
Aunque los tres últimos son formatos muy extendidos dentro de Kafka, cuando se hace uso de Schema Registry, buscamos que nos permita serializar en binario y que además soporte las restricciones del uso de un schema. Por lo que las mejores opciones para usar con Schema Registry serían las tres primeras, siendo AVRO las más usada. De esta manera vamos a ver en los siguientes puntos como tener un gobierno de eventos con Schema Registry y Avro.
Serialización con AVRO
Avro es una herramienta open source para la serialización que proviene del mundo de Hadoop. Entre sus principales características nos ofrece:
- Avro soporta tipos complejos como arrays, maps, etc, y puede trabajar con primitivas como int, boolean, String etc…
- Sus esquemas pueden ser definidos usando JSON.
- Podemos definir valores por defecto a nuestros campos y además podemos añadir documentación para describir cada campo.
- Muy robusto para schemas que pueden cambiar a lo largo del tiempo permitiendo evolucionar el schema.
Un ejemplo podría ser:
{
"type" : "record",
"name" : "User",
"namespace" : "com.example.models.avro",
"fields" : [
{"name" : "userID", "type" : "string", "doc" : "User ID of a web app"},
{"name" : "customerName", "type" : "string", "doc" : "Customer Name", "default": "Test User"}
]
}
Schema evolution con Schema Registry
Con el tiempo, lo más normal es que modifiquemos nuestros schemas guardados en nuestro Schema Registry, quizás añadimos algún campo o eliminamos. Y obviamente, de estos cambios deben ser conscientes todos los consumidores, no es muy apetecible que un sábado te llamen porque ha saltado una alerta debido a un cambio en el schema que no se ha notificado. Para evitar esos problemas y poder evolucionar el schema fácilmente, podemos versionar y evolucionar nuestros schemas guardados en nuestro Schema Registry.
Al ir evolucionando nuestro schema iremos generando nuevos schemas ids y nuevas versiones incrementales, con lo que siempre que se produce un cambio una nueva versión se genera. Pero, ¿Cómo sabe el consumidor en su microservicio si su versión es compatible?, pues para eso tenemos dos maneras diferentes:
- A través de un plugin de maven.
- Haciendo una petición Rest.
Para evolucionar nuestros schemas podemos hacer uso de diferentes aproximaciones que en función de la estrategia deberá ser compatible en el tiempo:
Backward Compatibility o Compatibilidad hacia atrás
El consumidor utilizando el nuevo schema puede leer sin problema los datos que se han generado con la anterior versión del Schema. Existen dos opciones dentro de la compatibilidad Backward:
- Backward: el consumidor puede procesar los schemas X o X-1.
- Backward Transitive: el consumidor puede procesar información producida por los schemas de versiones X, X-1 o X-2

Forward Compatibility o Compatibilidad hacia adelante
La opción forward permite la compatibilidad hacia adelante, es decir, que los datos producidos con un nuevo esquema pueden ser leídos por los consumidores que utilizan el último esquema.
En resumen, si generamos un nuevo schema con nueva versión, se va a permitir que la información producida se pueda leer por los consumidores usando el último schema. Dentro de esta opción, encontramos dos opciones más:
- Forward Transitive: En la que se podrá utilizar los schemas X, X-1 o X-2
- Fordward: En la que la compatibilidad hacia atrás será únicamente para un schema.
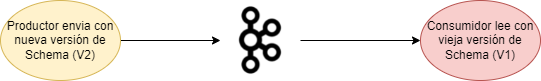
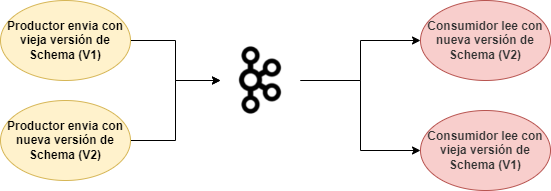
Full Compatibility o Compatibilidad Completa
Con Full Compatibility lo que vamos a tener es compatibilidad hacia adelante y hacia atrás. Es decir, la información antigua va a poder ser leída por nuevos schemas, y la información nueva va a poder ser leída por viejos schemas. Dentro de la Full Compatibility nos encontramos dos opciones:
- Full: Compatibilidad hacia adelante y atrás únicamente con el schema anterior.
- Full Transitive: Ambas compatibilidades (Adelante y atrás), compatibles con los schemas X, X-1 o X-2
No Compatibility Checking o Sin verificación de Compatibilidad
En algunas ocasiones puede ocurrir que no se quiera permitir compatibilidad entre versiones, para esas ocasiones se desactivará la compatibilidad.
Una vez hemos visto las diferentes formas de evolución de nuestros schmeas y como funciona Schema Registry es momento de ver un caso práctico.
Ejemplo de Gobierno de Eventos con Schema Registry y AVRO
En este punto vamos a ver un ejemplo de Gobierno de Eventos con Schema Registry y Avro, viendo como podemos utilizar las diferentes aproximación de evolución de eventos y como afectan al consumidor y productor en función de la elección.
Arrancar Schema Registry con Docker
A continuación vamos a hacer uso de Docker para entender mejor la evolución entre los Schemas con Avro dentro de un Schema Registry. Para poder realizar este ejemplo nos vamos a basar en la imágen fast-data-dev, la cual nos proporciona Kafka, Schema Registry y si Rest Proxy como interfaz Rest de Kafka, que viene perfecto para entornos de desarrollo.
version: '3'
services:
# kafka cluster.
kafka-cluster:
image: landoop/fast-data-dev:latest
environment:
ADV_HOST: 127.0.0.1
RUNTESTS: 0
FORWARDLOGS: 0
SAMPLEDATA: 0
ports:
- 2181:2181 # Zookeeper port
- 3030:3030 # Landoop UI port
- 8081-8083:8081-8083 # REST Proxy, Schema Registry, Kafka Connect ports
- 9581-9585:9581-9585 # JMX Ports
- 9092:9092 # Kafka Broker port
Para levantar nuestro docker utilizamos el comando :
docker-compose up -d #-d ejecuta en background
Una vez nuestros servicios están levantados accedemos a la consola de administración en el puerto 3030. La cual nos muestra una interfaz con los servicios que tenemos. http://localhost:3030.
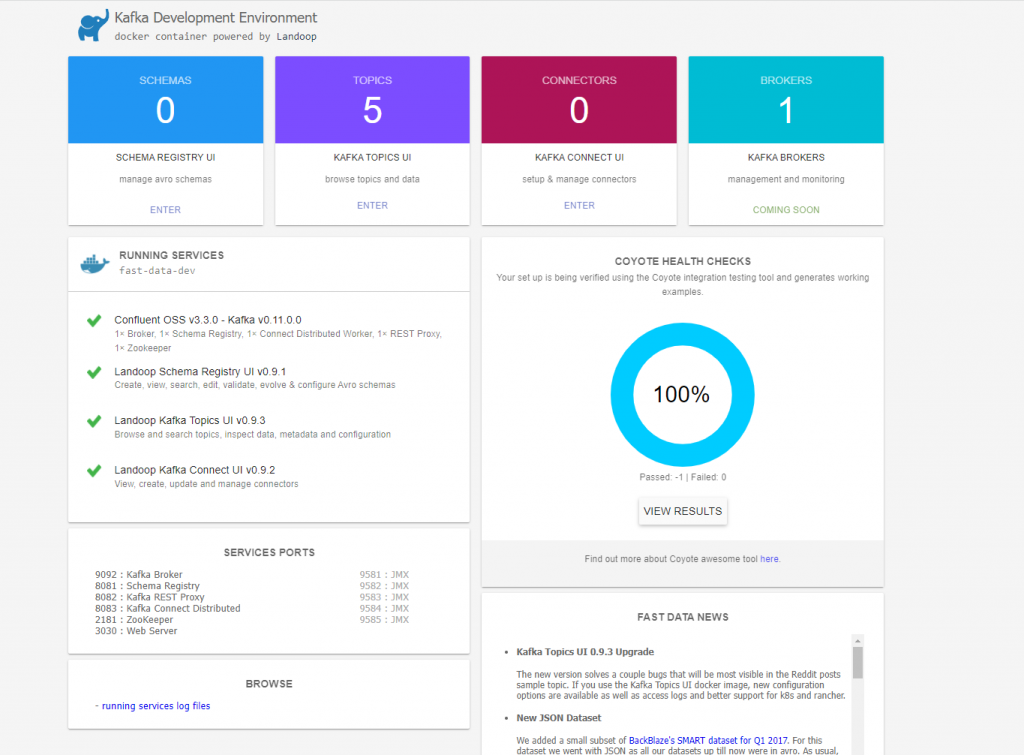
La interfar anterior nos proporciona información sobre los topics, brokers, schemas y conexiones que tenemos establecidas.
Crear Schema con compatibilidad Backward
Una vez hemos levantado nuestro docker compose y tenemos todo funcionando es momento vamos a crear un schema para analizar la compatibilidad backward de nuestro productor y consumidor. Compatibilidad Backward es aquella en la que el consumidor con el nuevo schema puede consumir mensajes del anterior.
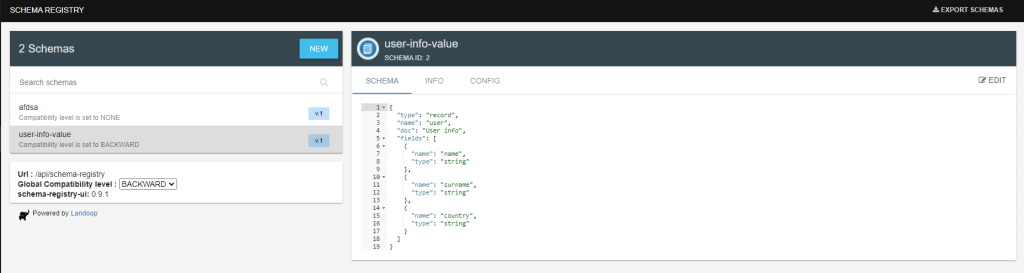
Para crear nuestro schema vamos a la url: http://localhost:3030/schema-registry-ui, en la que añadimos un nuevo schema, al pulsar nuevo te aparecerá un ejemplo de la siguiente manera:
{
"type": "record",
"name": "evolution",
"doc": "This is a sample Avro schema to get you started. Please edit",
"namespace": "com.landoop",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "number1",
"type": "int"
},
{
"name": "number2",
"type": "float"
}
]
}
vamos a modificar nuestro ejemplo para mostrar la información de un usuario de la siguiente manera:
{
"type": "record",
"name": "user",
"doc": "User info",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "surname",
"type": "string"
},
{
"name": "country",
"type": "string"
}
]
}
Pulsamos sobre validar y a continuación sobre crear. Una vez creado nos aparecerá las opciones de configuración el tipo de evolución, nosotros elegiremos Backward para nuestro ejemplo.
Producir y consumir mensajes usando Schema Registry
Vamos a hacer uso de confluent para utilizar un productor y consumidor que sean capaces de serializar y deserializar usando Avro. Para ello vamos a utilizar la imagen cp-schema-registry y utilizar los comandos de confluent para podrucir y consumir conectándonos a nuestro Schema Registry.
docker run -it --rm --net=host confluentinc/cp-schema-registry:latest bash
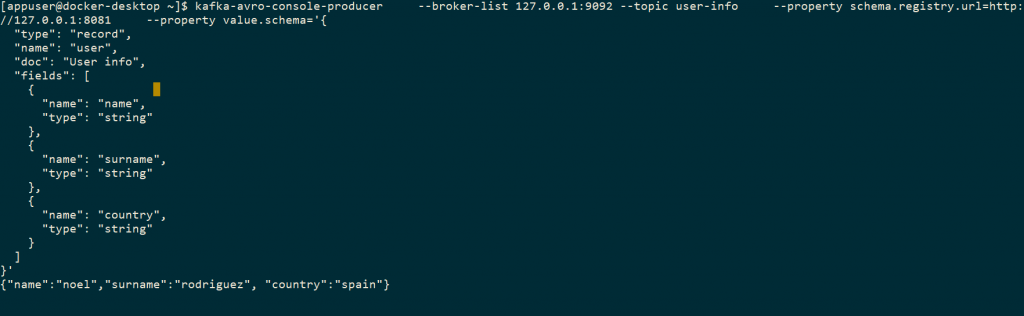
Para producir un mensaje vamos a utilizar el comando Kafka-avro-console-producer:
kafka-avro-console-producer \
--broker-list 127.0.0.1:9092 --topic user-info \
--property schema.registry.url=http://127.0.0.1:8081 \
--property value.schema='{
"type": "record",
"name": "user",
"doc": "User info",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "surname",
"type": "string"
},
{
"name": "country",
"type": "string"
}
]
}'
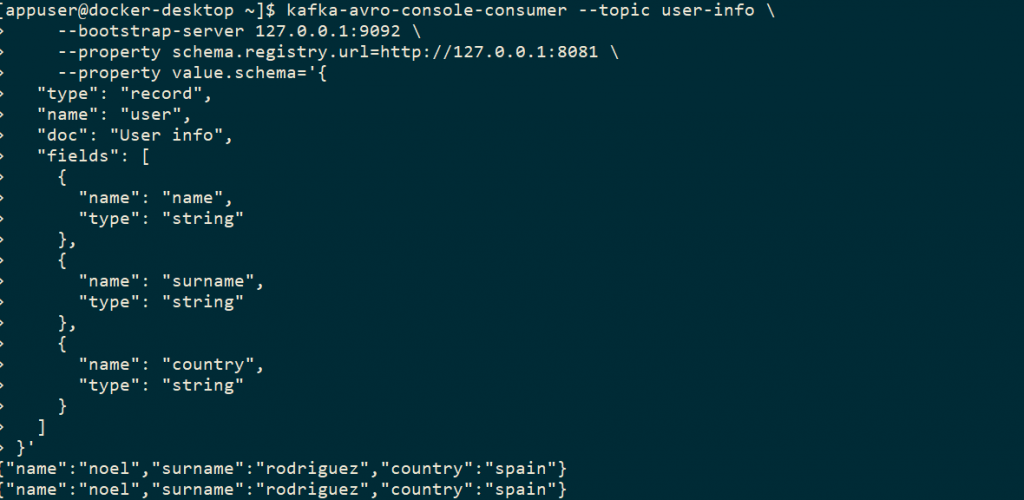
Para consumir vamos a utilizar el comando que nos proporciona Confluent : kafka-avro-console-consumer
kafka-avro-console-consumer --topic user-info \
--bootstrap-server 127.0.0.1:9092 \
--property schema.registry.url=http://127.0.0.1:8081 \
--property value.schema='{
"type": "record",
"name": "user",
"doc": "User info",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "surname",
"type": "string"
},
{
"name": "country",
"type": "string"
}
]
}'
Desde diferentes terminales vemos como es producido y consumido el siguiente mensaje:
{"name":"noel","surname":"rodriguez", "country":"spain"}
Productor:
Consumidor:
Evolución del Schema con compatibilidad Backward
Hemos comprobado que podemos enviar y recibir mensajes haciendo uso del Schema Registry de una manera correcta. Si intentamos enviar un mensaje con un formato incorrecto saltará un error de serialización de Avro. Ahora vamos a evolucionar nuestro Schema para ver como podemos seguir recibiendo mensajes con el formato antiguo teniendo ya uno nuevo, es decir, vamos a hacer uso de la compatibilidad Backward.
Para ello vamos a eliminar un campo y evolucionar el Schema a la versión V.2.
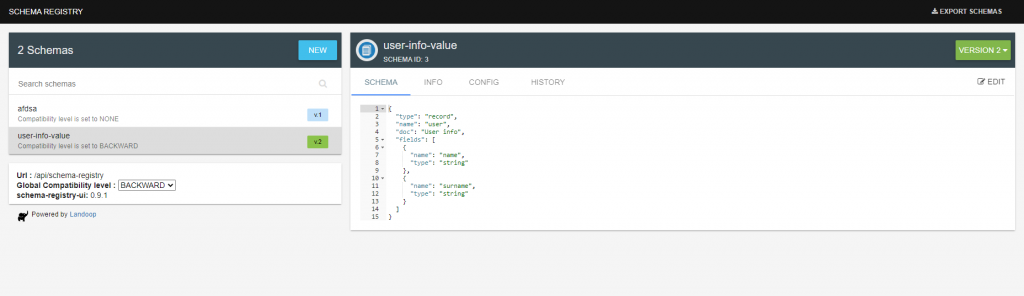
A continuación vamos a producir y consumir mensajes para ver como nuestro consumidor puede leer mensajes con el formato anterior de la versión V.1.0.
Dejamos el anterior productor y levantamos uno nuevo, con el formato de mensajes actual y vemos como nuestro consumidor con la versión V.2.0 es capaz de procesarlos.
kafka-avro-console-producer \
--broker-list 127.0.0.1:9092 --topic user-info \
--property schema.registry.url=http://127.0.0.1:8081 \
--property value.schema='{
"type": "record",
"name": "user",
"doc": "User info",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "surname",
"type": "string"
}
]
}'
Y utilizamos el siguiente mensaje:
{"name":"noel","surname":"rodriguez"}
En la compatibilidad backwar al enviar el mensaje podemos ver como nuestro consumidor es capaz de leer mensajes con el nuevo y el anterior formato sin ningún problema. Con la compatibilidad backward el productor no se actualiza siendo el consumidor el que evoluciona.
Evolucionar Schema con compatibilidad Forward
Vamos a editar nuestro schema para permitir la compatibilidad forward. La compatibilidad forward es aquella en la que el consumidor con el schema anterior es capaz de los los nuevos mensajes del productor con el schema nuevo.
Para ello vamos a la edición del schema y pulsamos sobre config y actualizamos con forward.
A continuación añadimos un nuevo campo a nuestro schema, city, y actualizamos a la versión V.3.0.
Creamos un nuevo productor con el formato nuevo y envíamos el mensaje:
{"name":"noel","surname":"rodriguez", "city":"madrid"}
Y vemos como nuestro consumidor es capaz de procesar el mensaje:
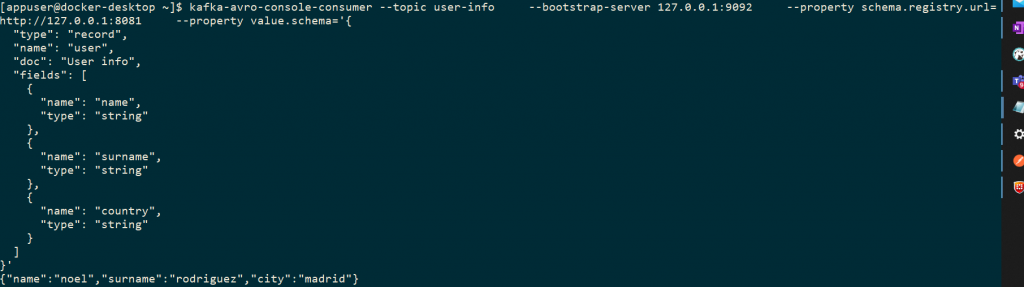
En este tipo de compatibilidad el consumidor no es necesario actualizarlo para la recepción de los nuevos mensajes.
Evolucionar Schema Registry con compatibilidad Full
Cuando evolucionamos un Schema con compatibilidad full, estamos haciendo que sea compatible Backward y Forward, para ello vamos a nuestro Schema, pulsamos editar y lo transformamos a Full.
Para poder probar esta funcionalidad vamos a crear un nuevo schema y marcarlo como full, con el topic user-info-full:
{
"type": "record",
"name": "user",
"doc": "User info",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "surname",
"type": "string"
},
{
"name": "county",
"type": "string"
}
]
}
Evolucionomos la versión eliminando y añadiendo un campo, city como opcional:
{
"type": "record",
"name": "user",
"doc": "User info",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "surname",
"type": "string"
},
{
"name": "county",
"type": "string"
},
{
"name": "city",
"type": [
"string",
"null"
],
"default": "null"
}
]
}
Una vez editado y generado una nueva versión V.4 de nuestro schema arrancamos un consumidor y un productor con las nuevas versiones y enviamos mensajes:
kafka-avro-console-producer \
--broker-list 127.0.0.1:9092 --topic user-info-full \
--property schema.registry.url=http://127.0.0.1:8081 \
--property value.schema='{
"type": "record",
"name": "user",
"doc": "User info",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "surname",
"type": "string"
},
{
"name": "county",
"type": "string"
},
{
"name": "city",
"type": [
"string",
"null"
],
"default": "null"
}
]
}'
kafka-avro-console-consumer --topic user-info-full \
--bootstrap-server 127.0.0.1:9092 \
--property schema.registry.url=http://127.0.0.1:8081 \
--property value.schema='{
"type": "record",
"name": "user",
"doc": "User info",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "surname",
"type": "string"
},
{
"name": "county",
"type": "string"
},
{
"name": "city",
"type": [
"string",
"null"
],
"default": "null"
}
]
}'
Ahora para ver que tenemos compatibilidad total vamos a hacer dos pruebas:
- Enviar mensajes con la versión inicial del schema (con country).
- Enviar mensajes con la nueva versión del schema.
En este tipo de compatibilidad se evoluciona tanto el consumidor como el productor y pueden procesar ambas versiones de los schemas sin problemas.
Tips con Schema Registry
- Siempre que evoluciones un Schema, es recomendable añadir valores por defectho y es mejor no borrar campos obligatorios.
- Siempre que se pueda añadir valores por defecto.
- No renombrar los campos de nuestros schemas, es mejor añadir un campo nuevo.
Conclusión de un gobierno de eventos con Schema Registry y Avro
En este artículo sobre gobierno de eventos con Schema Registry y Avro, hemos visto una introducción a lo que Schema Registry nos aporta a la hora de trabajar con kafka, así como sus diferentes opciones de implementación.
El uso de las diferentes aproximaciones de evolución de los schemas dependerá de la situación en la que te encuentres. Con Full sabemos que no habrá problemas, sino queremos actualizar el consumidor mejor forward, y sino queremos actualizar el productor entonces backward.
Espero que te sea de utilidad el artículo y cualquier duda no dudes en contactar o dejar un comentario.
Si necesitas más información puedes escribirnos un comentario o un correo electrónico a refactorizando.web@gmail.com o también nos puedes contactar por nuestras redes sociales Facebook o twitter y te ayudaremos encantados!